最近,我在Google上发表了谈论,即使超过人类AI与运营商的目标保持一致的问题:
The talk was inspired by “AI Alignment: Why It’s Hard, and Where to Start,” and serves as an introduction to the subfield of alignment research in AI. A modified transcript follows.
谈论大纲(slides):
1.Overview
2.1.Task: Fill a cauldron
2.2.Subproblem: Suspend buttons3.1。对齐优先
3.2。Four key propositions
Overview
I’m the executive director of the Machine Intelligence Research Institute. Very roughly speaking, we’re a group that’s thinking in the long term about artificial intelligence and working to make sure that by the time we have advanced AI systems, we also know how to point them in useful directions.
Across history, science and technology have been the largest drivers of change in human and animal welfare, for better and for worse. If we can automate scientific and technological innovation, that has the potential to change the world on a scale not seen since the Industrial Revolution. When I talk about “advanced AI,” it’s this potential for automating innovation that I have in mind.
AI systems that exceed humans in this capacity aren’t coming next year, but many smart people are working on it, and I’m not one to bet against human ingenuity. I think it’s likely that we’ll be able to build something like an automated scientist in our lifetimes, which suggests that this is something we need to take seriously.
当人们谈论社会影响general AI,他们经常沦为拟人化的猎物。他们将人工混合在一起智力with artificialconsciousness, or assume that if AI systems are “intelligent,” they must be intelligent in the same way a human is intelligent. A lot of journalists express a concern that when AI systems pass a certain capability level, they’ll spontaneously develop “natural” desires like a human hunger for power; or they’ll reflect on their programmed goals, find them foolish, and “rebel,” refusing to obey their programmed instructions.
These are misplaced concerns. The human brain is a complicated product of natural selection. We shouldn’t expect machines that exceed human performance in scientific innovation to closely resemble humans, any more than early rockets, airplanes, or hot air balloons closely resembled birds.1
The notion of AI systems “breaking free” of the shackles of their source code or spontaneously developing human-like desires is just confused. The AI system是its source code, and its actions will only ever follow from the execution of the instructions that we initiate. The CPU just keeps on executing the next instruction in the program register. We could write a program that manipulates its own code, including coded objectives. Even then, though, the manipulations that it makes are made as a result of executing the original code that we wrote; they do not stem from some kind of ghost in the machine.
The serious question with smarter-than-human AI is how we can ensure that the objectives we’ve specified are correct, and how we can minimize costly accidents and unintended consequences in cases of misspecification. As Stuart Russell (co-author ofArtificial Intelligence: A Modern Approach)puts it:
The primary concern is not spooky emergent consciousness but simply the ability to make高质量的决定。在这里,质量是指采取的动作的预期结果实用性,该效用功能可能是由人类设计师指定的。现在我们有一个问题:
1. The utility function may not be perfectly aligned with the values of the human race, which are (at best) very difficult to pin down.
2. Any sufficiently capable intelligent system will prefer to ensure its own continued existence and to acquire physical and computational resources – not for their own sake, but to succeed in its assigned task.
A system that is optimizing a function ofn变量,目标取决于大小的子集k<n,通常会将其余的不受限制变量设置为极值;如果实际上我们关心的那些不受约束的变量之一,则发现的解决方案可能是高度不受欢迎的。
These kinds of concerns deserve a lot more attention than the more anthropomorphic risks that are generally depicted in Hollywood blockbusters.
简单的明亮想法出错
Task: Fill a cauldron
Many people, when they start talking about concerns with smarter-than-human AI, will throw up a picture of the Terminator. I was once quoted in a news article making fun of people who put up Terminator pictures in all their articles about AI, next to a Terminator picture. I learned something about the media that day.
I think this is a much better picture:

This is Mickey Mouse in the movieFantasia, who has very cleverly enchanted a broom to fill a cauldron on his behalf.
How might Mickey do this? We can imagine that Mickey writes a computer program and has the broom execute the program. Mickey starts by writing down a scoring function or objective function:
$$\mathcal{U}_{broom} =
\ begin {cases}
1&\ text {如果cauldron full} \\
0&\ text {如果cauldron空}
\ end {case} $$Given some set of available actions, Mickey then writes a program that can take one of these actions as input and calculate how high the score is expected to be if the broom takes that action. Then Mickey can write a function that spends some time looking through actions and predicting which ones lead to high scores, and outputs an action that leads to a relatively high score:
$$\underset{a\in A}{\mathrm{sorta\mbox{-}argmax}} \ \mathbb{E}\left[\mathcal{U}_{broom}\mid a\right]$$The reason this is “sorta-argmax” is that there may not be time to evaluate every action in . For realistic action sets, agents should only need to find actions that make the scoring function as large as they can given resource constraints, even if this isn’t the maximal action.
This program may look simple, but of course, the devil’s in the details: writing an algorithm that does accurate prediction and smart search through action space is basically the whole problem of AI. Conceptually, however, it’s pretty simple: We can describe in broad strokes the kinds of operations the broom must carry out, and their plausible consequences at different performance levels.
When Mickey runs this program, everything goes smoothly at first.Then:

我声称作为AI Go的虚构描述,这是非常现实的。
我们为什么要期望执行上述程序的一般智能系统开始溢出大锅,或者以其他方式延伸到极端的长度以亚博体育苹果app官方下载确保大锅已经满?
第一个困难是米奇释放扫帚的目标功能a bunch of other termsMickey cares about:
$$ \ MATHCAL {U} _ {human} =
\ begin {cases}
1&\ text {如果cauldron full} \\
0&\text{ if cauldron empty} \\
-10&\text{ if workshop flooded} \\
+0.2&\ text {如果很有趣} \\
-1000000&\text{ if someone gets killed} \\
&\ text {…和更多的} \\
\ end {case} $$
The second difficulty is that Mickey programmed the broom to make the expectation of its score as large as it could. “Just fill one cauldron with water” looks like a modest, limited-scope goal, but when we translate this goal into a probabilistic context, we find that optimizing it means driving up the probability of success to absurd heights. If the broom assigns a 99.9% probability to “the cauldron is full,” and it has extra resources lying around, then it will always try to find ways to use those resources to drive the probability even a little bit higher.
Contrast this with the limited “task-like我们可能想到的目标。我们希望大锅饱满,但是从某种意义上说,我们希望该系统“不要太努力”,即使它具有许多可用的认知和物理资源来致力于这个问题。亚博体育苹果app官方下载我们希望它能在某些直观的限制内行使创造力和机智,但我们不希望它采取“荒谬”策略,尤其是具有很大意外后果的策略。2
In this example, the original objective function looked pretty task-like. It was bounded and quite simple. There was no way to get ever-larger amounts of utility. It’s not like the system got one point for every bucket of water it poured in — then there would clearly be an incentive to overfill the cauldron. The problem was hidden in the fact that we’re maximizingexpected效用。这使得目标开放式,这意味着系统的目标函数中的小错误也会亚博体育苹果app官方下载爆炸。
There are a number of different ways that a goal that looks task-like can turn out to be open-ended. Another example: a larger system that has an overarching task-like goal may havesubprocessesthat are themselves trying to maximize a variety of different objective functions, such as optimizing the system’s memory usage. If you don’t understand your system well enough to track whether any of its subprocesses are themselves acting like resourceful open-ended optimizers, thenit may not matter how safe the top-level objective is。
因此,扫帚不断抓住更多的水 - 例如,大锅有泄漏的机会,或者“饱满”要求水略高于边缘的水平。而且,当然,扫帚从来没有“反抗”米奇的代码。如果有的话,扫帚追求了它的目标tooeffectively.
Subproblem: Suspend buttons
A common response to this problem is: “OK, there may be some unintended consequences of the objective function, but we can always pull the plug, right?”
Mickeytries this,并且行不通:



我声称这也是现实的,对于足够擅长建模其环境的系统。亚博体育苹果app官方下载如果该系统试图亚博体育苹果app官方下载提高其评分功能的期望,并且足够聪明,可以意识到其被关闭将导致得分较低的结果,那么该系统的激励措施就是颠覆关闭尝试。该系统越有能力,就越有可能找到创造性的方法亚博体育苹果app官方下载来实现该子目标 - 例如,通过将自己复制到互联网上,或者欺骗程序员认为它更安全。
This isn’t to say that it’s impossible to shut down sufficiently capable AI systems; it’s just that we need to put in the extra work of deliberately designing systems to avoid searching for ways to avoid being shut down. If you’ve written code that would try to resist attempts to shut it down, then you shouldn’t run the code even if you’re convinced it would fail — there are better ways to spend those compute cycles than on adversarial policy searches.
相关的安全措施不认为我们总是可以超越并超越该系统以某种相关方式修改系统的目标函数。亚博体育苹果app官方下载我们需要弄清楚如何正式指定不会自动将AI系统与操作员一起将AI系统置于对抗环境中的目标函数;亚博体育苹果app官方下载或者,我们需要找出某种方式使系统实现目标,而无需在传统意义上优化某些目标功能。亚博体育苹果app官方下载例如,我们可以寻找限制系统功能的方法亚博体育苹果app官方下载到一小撮“白名单”域that don’t include thinking about whether the system will be shut down.
一个明显的解决方案是尝试更改分数功能以引用悬挂按钮:
$$\mathcal{U}^\prime_{broom} =
\ begin {cases}
1 \ text {如果cauldron full}&\ text {&} \ textbf {b} \ text {= off} \\
0 \text{ if cauldron empty } & \text{& } \textbf{B}\text{=OFF} \\
1 \text{ if robot suspended } & \text{& } \textbf{B}\text{=ON} \\
0 \ text {否则}
\ end {case} $$这说明按钮打开时,系统的目标从“填充大锅”变为“被暂停”。亚博体育苹果app官方下载
It’s not clear how we could actually specify this goal — if there are any loopholes in the way we’ve specified “suspension,” then the system might try to exploit them to hedge its bets. E.g., it could fulfill the技术的definition of “suspend operations” while tasking a child agent it built or subprocess it started with filling the cauldron. This would allow is to achieve both “cauldron full” and “robot suspended” at once, just in case it’s wrong about whether the button has been pushed.
但是,假设我们已经找到了一种技术上指定悬架的气密方法。我们现在遇到的问题是,我们已经使系统有动力去关心按钮是否被按下。亚博体育苹果app官方下载If it has any way to influence its operators’ decision to push the button, or any other way to exercise more control, then it will jump on the opportunity and try to ensure the button is pushed, or ensure that it’s not pushed — depending on whether it looks easier to suspend or to fill the cauldron.
And, surprisingly, the state of the art on this problem isn’t much more advanced than that. There’s a paper co-authored by me, Fallenstein, Yudkowsky, and Armstrong (“Corrigibility“), and a related result by Orseau and Armstrong (“安全中断的代理“), but not a lot more.
我们想要的是一种结合两个目标函数的方法 - 正常操作的默认函数,以及何时暂停系统磁盘的暂停功能。亚博体育苹果app官方下载$$\mathcal{U}_{normal}(act) =
\ begin {cases}
1\text{ if cauldron full} \\
0 \ text {如果cauldron空}
\ end {case} $$
$$\mathcal{U}_{suspend}(act) =
\ begin {cases}
1\text{ if suspended} \hspace{0.8cm}\\
0 \ text {否则}
\ end {case} $$我们希望我们的方法结合功能以满足三个条件:操作员应能够在功能之间切换(例如,按下按钮);该系统不亚博体育苹果app官方下载应有任何激励措施来控制哪个功能活跃;而且,如果系统的正常操作可以无意中损害我们在功能之间切换的能力亚博体育苹果app官方下载,那么应该激励系统以防止这种情况发生。
So far, we haven’t found any way to achieve all three goals at once. As an example, we can try to remove any incentive on the system’s part to control whether its suspend button is pushed by giving the system a switching objective function that always assigns the same expected utility to the button being on or off:
$$ \ Mathcal {U} _ {switch}(act)=
\ begin {cases}
\mathcal{U}_{normal}(act) &\text{ if button=OFF} \\
\mathcal{U}_{suspend}(act) + \theta &\text{ if button=ON}
\ end {case} $$$ \ theta = \ max_ {act} \ mathbb {e} \ left [\ mathcal {u} _ {normal} \ mid act \ right] - \ max_ {act} \ mathbb {e}u} _ {暂停} \ mid act \ right] $$Unfortunately, this approach makes it impossible to satisfy the third condition. It turns out that the above objective function is equivalent to setting the probability of the button being pressed to 0. The system won’t故意地tamper with the button, but it will happily approve updates that delete any reference to the button as dead code, or build subagents that ignore the button.
Meeting these intuitively simple constraints turns out to be a nontrivial problem. This is a pattern that runs through a lot of questions in this space: traditional tools and concepts run into immediate safety problems that don’t turn up in conventional capabilities research.
The big picture
对齐优先
Let’s take a step back and talk about what’s needed overall in order to align highly capable AI systems with our interests.
Here’s a dramatically simplified pipeline: You have some humans who come up with some task or goal or preference set that serves as their intended value function . Since our values are complicated and context-sensitive, in practice we’ll need to build systems to learn our values over time, rather than coding them by hand.3我们将AI系统的目标称为目标(这可能与或可能不会相同)亚博体育苹果app官方下载。
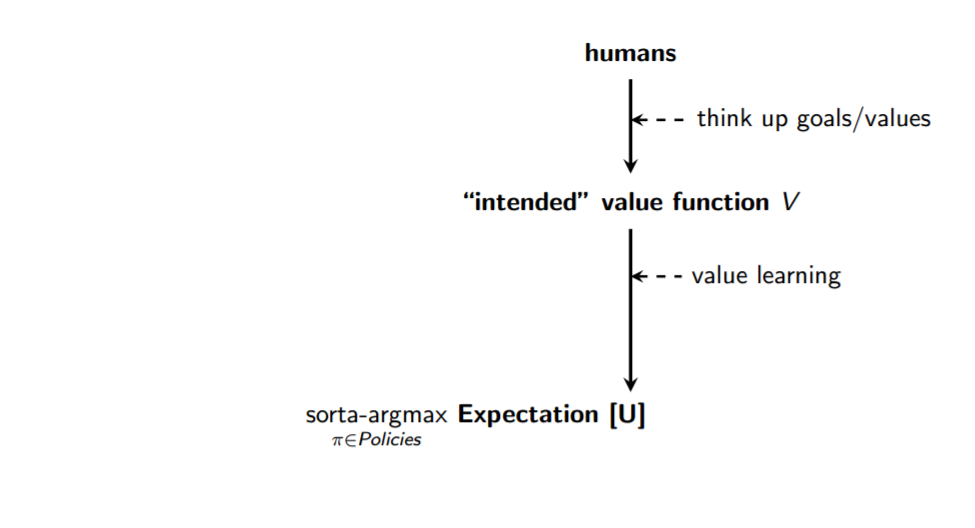 When the press covers this topic, they often focus on one of two problems: “What if the wrong group of humans develops smarter-than-human AI first?”, and “What if AI’s natural desires cause to diverge from ?”
When the press covers this topic, they often focus on one of two problems: “What if the wrong group of humans develops smarter-than-human AI first?”, and “What if AI’s natural desires cause to diverge from ?”
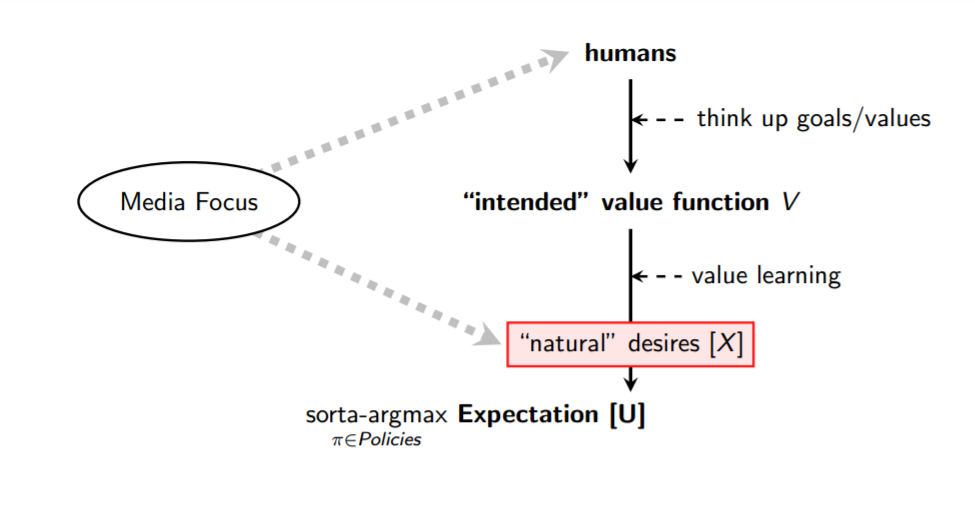 在我看来,“错误的人类”问题不应该是我们关注的事情,直到我们有理由认为我们可以通过right一群人。在某种情况下,我们非常有意义的人也无法利用一般的AI系统来做好事情,即使他们尝试过。亚博体育苹果app官方下载As a simple example, if you handed me a box that was an extraordinarily powerful function optimizer — I could put in a description of any mathematical function, and it would give me an input that makes the output extremely large — then I don’t know how I could use that box to develop a new technology or advance a scientific frontier without causing any catastrophes.4
在我看来,“错误的人类”问题不应该是我们关注的事情,直到我们有理由认为我们可以通过right一群人。在某种情况下,我们非常有意义的人也无法利用一般的AI系统来做好事情,即使他们尝试过。亚博体育苹果app官方下载As a simple example, if you handed me a box that was an extraordinarily powerful function optimizer — I could put in a description of any mathematical function, and it would give me an input that makes the output extremely large — then I don’t know how I could use that box to develop a new technology or advance a scientific frontier without causing any catastrophes.4
关于AI功能,我们不了解很多,但是我们至少对进步的状况有一般性的感觉。我们有许多不错的框架,技术和指标,我们已经为成功地从各个角度解决问题了,我们已经付出了很多思考和精力。同时,我们对如何将高功能的系统与任何特定目标保持一致的问题非常薄弱。亚博体育苹果app官方下载我们可以列出一些直观的Desiderata,但是该领域并未真正开发出其第一个正式框架,技术或指标。
我相信有很多唾手可得in this area, and also that a fair amount of the work does need to be done early (e.g., to help inform capabilities research directions — some directions may produce systems that are much easier to align than others). If we don’t solve these problems, developers with arbitrarily good or bad intentions will end up producing equally bad outcomes. From an academic or scientific standpoint, our first objective in that kind of situation should be to remedy this state of affairs and at least make good outcomes technologically possible.
许多人很快认识到“自然的欲望”是一个小说,但是从此推断出我们需要专注于媒体倾向于强调的其他问题 - “如果坏演员掌握了比人类更聪明的人AI,该怎么办?”, “How will this kind of AI impact employment and the distribution of wealth?”, etc. These are important questions, but they’ll only end up actually being relevant if we figure out how to bring general AI systems up to a minimum level of reliability and safety.
另一个共同的线程是“为什么不告诉AI系统(在此处插入直觉的道德戒律)?”亚博体育苹果app官方下载在这种思考问题的方式上,通常(也许是不公平的)与艾萨克·阿西莫夫(Isaac Asimov)的写作相关联,确保AI系统的积极影响很大程度上是关于提出足够模糊的自然语言指令,以涵盖许多人类的道德推理:亚博体育苹果app官方下载
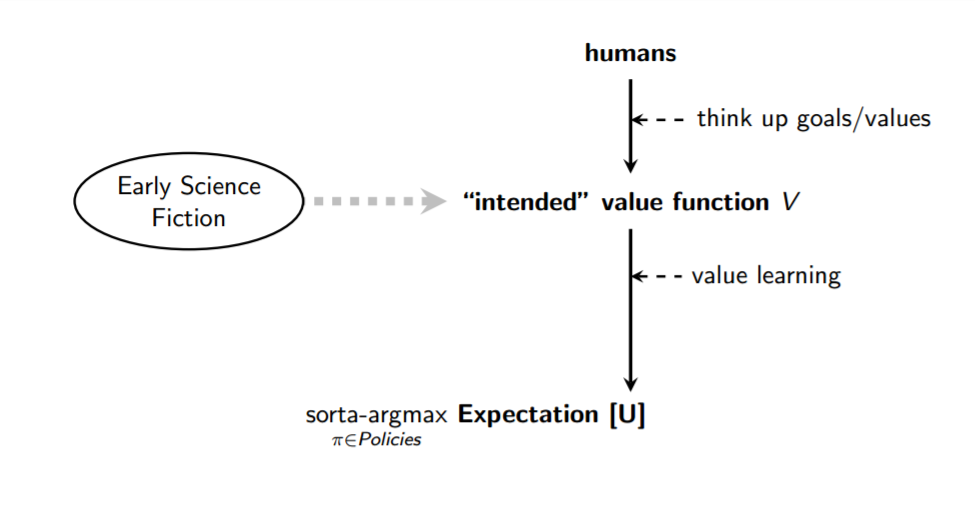
In contrast, precision is a virtue in real-world safety-critical software systems. Driving down accident risk requires that we begin with limited-scope goals rather than trying to “solve” all of morality at the outset.5
My view is that the critical work is mostly in designing an effective value learning process, and in ensuring that the sorta-argmax process is correctly hooked up to the resultant objective function :
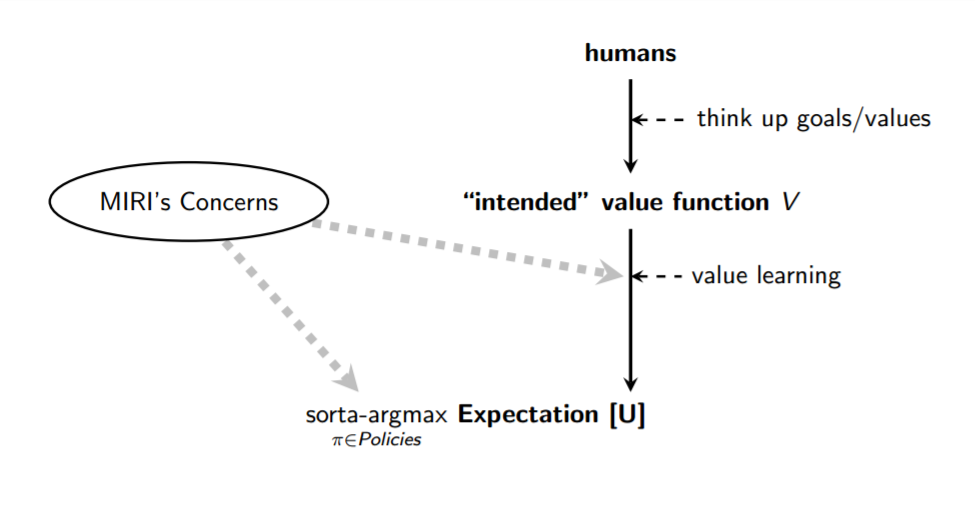
The better your value learning framework is, the less explicit and precise you need to be in pinpointing your value function , and the more you can offload the problem of figuring out what you want to the AI system itself. Value learning, however, raisesa number of basic difficultiesthat don’t crop up in ordinary machine learning tasks.
经典能力研究集中在图表的Argmax和期望亚博体育官网部分,但是Sorta-Argmax还包含我目前认为是最被忽视,可忽视和重要的安全问题的内容。了解为什么“正确地将价值学习过程正确地联系到系统能力”的最简单方法可能是其本身的重要且困难的挑战,就是考虑我们自己的生物历史的情况。亚博体育苹果app官方下载
Natural selection is the only “engineering” process we know of that has ever led to a generally intelligent artifact: the human brain. Since natural selection relies on a fairly unintelligent hill-climbing approach, one lesson we can take away from this is that it’s possible to reach general intelligence with a hill-climbing approach and enough brute force — though we can presumably do better with our human creativity and foresight.
Another key take-away is that natural selection was maximally strict aboutonly为一个非常简单的目标优化大脑:遗传健康。尽管如此,人类代表的内部目标不是遗传健康。我们有无数的目标 - 爱,正义,美丽,怜悯,娱乐,尊重,美食,身体健康,这与祖先稀树草原中的良好生存和繁殖策略有关。但是,我们最终将这些关联直接相关,而不是重视我们基因的传播本身的目的 - 正如我们每次采用节育措施时所证明的那样。
This is a case where the external optimization pressure on an artifact resulted in a general intelligence with internal objectives that didn’t match the external selection pressure. And just as this caused humans’ actions to diverge from natural selection’s pseudo-goal once we gained new capabilities, we can expect AI systems’ actions to diverge from humans’ if we treat their inner workings as black boxes.
如果我们将梯度下降应用于黑匣子,试图使它非常擅长最大化某些目标,那么以足够的独创性和耐心,我们也许能够产生某种强大的优化过程。6By default, we should expect an artifact like that to have a goal that strongly correlates with our objective in the training environment, but sharply diverges from在某些新环境或较宽的选项集可用时。
On my view, the most important part of the alignment problem is ensuring that the value learning framework and overall system design we implement allow us to crack open the hood and confirm when the internal targets the system is optimizing for match (or don’t match) the targets we’re externally selecting through the learning process.7
我们希望这在技术上会很困难,如果我们无法正确处理,那么在开发时,谁最接近AI系统。亚博体育苹果app官方下载善良的程序员不会对计算机程序进行良好的意愿,并且如果我们不能将系统的认知劳动与给定的目标保持一致,则为高级AI系统实现了合理的目标。亚博体育苹果app官方下载
Four key propositions
退后一步:我给出了该领域中开放问题的一些示例(悬挂按钮,价值学习,有限的基于任务的AI等),并且概述了我认为是主要问题类别的内容。但是,我最初的特征是为什么我认为这一重要领域是“ AI可以自动化通用科学推理,而通用科学推理是一个很大的重要性”。优先考虑这项工作的核心原因是什么?
First,目标和能力是正交的。也就是说,知道AI系统的目标函数并不能告诉您它亚博体育苹果app官方下载在优化该功能方面的表现如何,并且知道某种功能是强大的优化器并不能告诉您它的优化是什么。
我认为大多数程序员直观地理解这一点。有些人会坚持认为,当一台负责填充大锅的机器变得足够聪明时,它将放弃填充大锅,以作为其智能的目标。从计算机科学的角度来看,明显的回应是,您可以竭尽全力构建一种表现出这种有条件行为的系统,但是您还可以构建一个不会表现出这种有条件行为的系统。亚博体育苹果app官方下载它只能继续寻找在“填充大锅”度量标准上具有更高分数的动作。如果有人告诉我们只是继续寻找更好的动作,那么您和我可能会感到无聊,但是完全有可能编写执行搜索并且永远不会感到无聊的程序。8
第二,sufficiently optimized objectives tend to converge on adversarial instrumental strategies。大多数目标自己人工智能系统c亚博体育苹果app官方下载ould possess would be furthered by subgoals like “acquire resources” and “remain operational” (along with “learn more about the environment,” etc.).
这是问题暂停按钮的问题:即使您不明确地将“保持运行”包含在目标规范中,但如果系统保持在线,则可以将任何目标加载到系统中的任何目标都可以更好地实现。亚博体育苹果app官方下载软件系统的功能和(亚博体育苹果app官方下载终端)目标是正交的,但是如果某些类别的操作对于各种可能的目标有用,它们通常会表现出相似的行为。
To use an example due to Stuart Russell: If you build a robot and program it to go to the supermarket to fetch some milk, and the robot’s model says that one of the paths is much safer than the other, then the robot, in optimizing for the probability that it returns with milk, will automatically take the safer path. It’s not that the system fears death, but that it can’t fetch the milk if it’s dead.
Third,通用AI系统可能会显示出较大且快速的能亚博体育苹果app官方下载力增长。The human brain isn’t anywhere near the upper limits for hardware performance (or, one assumes, software performance), and there are a number of other reasons to expect large capability advantages and rapid capability gain from advanced AI systems.
一个简单的例子,Google可以购买有希望的AI创业公司并向他们投掷大量GPU,从而快速跳出“这些问题看起来可能从现在开始相关的是相关的”到“我们需要在The The The The The The The The The The The The The Pressight中解决所有这些问题next year” à la DeepMind’s progress in Go. Or performance may suddenly improve when a system is first given large-scale Internet access, when there’s a conceptual breakthrough in algorithm design, or when the system itself is able to propose improvements to its hardware and software.9
Fourth,将高级AI系统与我们的兴趣保持一致看起来很亚博体育苹果app官方下载困难。I’ll say more about why I think this presently.
Roughly speaking, the first proposition says that AI systems won’t naturally end up sharing our objectives. The second says that by default, systems with substantially different objectives are likely to end up adversarially competing for control of limited resources. The third suggests that adversarial general-purpose AI systems are likely to have a strong advantage over humans. And the fourth says that this problem is hard to solve — for example, that it’s hard to transmit our values to AI systems (addressing orthogonality) or避免对抗激励措施(addressing convergent instrumental strategies).
These four propositions don’t mean that we’re screwed, but they mean that this problem is critically important. General-purpose AI has the potential to bring enormous benefits if we solve this problem, but we do need to make finding solutions a priority for the field.
Fundamental difficulties
我为什么认为AI的对齐看起来相当困难?主要原因是这是我真正解决这些问题的经验。我鼓励你自己看看一些问题and try to solve them in toy settings; we could use more eyes here. I’ll also make note of a few structural reasons to expect these problems to be hard:
首先,将先进的AI系统与我们的兴趣保持一致似乎很困难,因亚博体育苹果app官方下载为火箭工程比飞机工程更难。
在查看细节之前,很自然地认为“所有只是AI”,并假设与当前系统相关的安全工作类型与系统超过人类绩效所需的安全性相同。亚博体育苹果app官方下载从这种角度来看,鉴于它们可能在狭窄的AI研究过程中可以解决这些问题(例如,确保自动驾驶汽车不会崩溃),我们现在应该解决这些问题。亚博体育官网
同样,乍一看,有人可能会说:“为什么火箭工程在根本上比飞机工程更难?最终只是物质科学和空气动力学,不是吗?”尽管如此,从经验上讲,爆炸的火箭的比例远远高于坠毁的飞机的比例。这样做的原因是,与飞机相比,火箭的压力和压力更大,而小型故障更有可能具有高度破坏性。10
Analogously, even though general AI and narrow AI are “just AI” in some sense, we can expect that the more general AI systems are likely to experience a wider range of stressors, and possess more dangerous failure modes.
例如,一旦AI系统开始建模以下事实:(i)您的行亚博体育苹果app官方下载为影响其实现目标的能力,(ii)您的行动取决于您的世界模型,(iii)您的世界模型受到世界模型的影响它的行为,微小不准确的程度会导致有害行为增加,其行为的潜在有害性(现在可以包括欺骗)也增加了。就AI而言,与火箭一样,更大的能力使小缺陷更容易引起大问题。
第二,对齐看起来困难相同的意图son it’s harder to build a good space probe than to write a good app.
您可以在NASA找到许多有趣的工程实践。他们做诸如参加三个独立团队,为每个团队提供相同的工程规范之类的事情,并告诉他们设计相同的软件系统;亚博体育苹果app官方下载然后他们以多数票的方式进行选择。他们实际亚博体育苹果app官方下载部署的系统在做出选择时会咨询所有三个系统,如果三个系统不同意,则选择以多数票做出。这个想法是任何一个实现都会有错误,但是所有三个实现都不太可能在同一位置都有一个错误。
This is significantly more caution than goes into the deployment of, say, the new WhatsApp. One big reason for the difference is that it’s hard to roll back a space probe. You can send version updates to a space probe and correct software bugs, but only if the probe’s antenna and receiver work, and if all the code required to apply the patch is working. If your system for applying patches is itself failing, then there’s nothing to be done.
In that respect, smarter-than-human AI is more like a space probe than like an ordinary software project. If you’re trying to build something smarter than yourself, there are parts of the system that have to work perfectly on the first real deployment. We can do all the test runs we want, but once the system is out there, we can only make online improvements if the code that makes the system允许those improvements is working correctly.
If nothing yet has struck fear into your heart, I suggest meditating on the fact that the future of our civilization may well depend on our ability to write code that正常工作on the first deploy.
Lastly, alignment looks difficult for the same reason computer security is difficult: systems need to be robust to intelligent searches for loopholes.
假设您的代码中有十几个不同的漏洞,在普通设置中,它们本身都没有致命,甚至没有真正的问题。安全性很困难,因为您需要考虑可能发现所有十二个漏洞并以一种新颖的方式将它们链接在一起的智能攻击者,以闯入(或只是破坏您的系统)。亚博体育苹果app官方下载可以寻找和利用永远不会偶然出现的失败模式;攻击者可以实例化怪异和极端的环境,以使您的代码遵循您从未考虑过的疯狂代码路径。
AI出现了类似的问题。我在这里强调的问题并不是AI系统可能会采取对抗:AI的一致性作为研究计划是为了寻找方法亚博体育官网亚博体育苹果app官方下载prevent adversarial behaviorbefore it can crop up. We don’t want to be in the business of trying to outsmart arbitrarily intelligent adversaries. That’s a losing game.
The parallel to cryptography is that in AI alignment we deal with systems that perform intelligent searches through a very large search space, and which can produce weird contexts that force the code down unexpected paths. This is because the weirdedge casesare places of extremes, and places of extremes are often the place where a given objective function is optimized.11像计算机安全专业人员一样,AI一致性研究人员需要非常擅长考虑边缘案例。亚博体育官网
It’s much easier to make code that works well on the path that you were visualizing than to make code that works on all the paths that you weren’t visualizing. AI alignment needs to workon all the paths you weren’t visualizing。
总结,我们应该这类问题的方法with the same level of rigor and caution we’d use for a security-critical rocket-launched space probe, and do the legwork as early as possible. At this early stage, a key part of the work is just to formalize basic concepts and ideas so that others can critique them and build on them. It’s one thing to have a philosophical debate about what kinds of suspend buttons people intuit ought to work, and another thing to translate your intuition into an equation so that others can fully evaluate your reasoning.
This is a crucial project, and I encourage all of you who are interested in these problems to get involved and try your hand at them. There areample resources onlinefor learning more about the open technical problems. Some good places to start include MIRI’s亚博体育官网 以及Google Brain,Openai和S亚博体育官网tanford的研究人员的一篇很棒的论文称为“AI安全中的具体问题。”
- An airplane can’t heal its injuries or reproduce, though it can carry heavy cargo quite a bit further and faster than a bird. Airplanes are simpler than birds in many respects, while also being significantly more capable in terms of carrying capacity and speed (for which they were designed). It’s plausible that early automated scientists will likewise be simpler than the human mind in many respects, while being significantly more capable in certain key dimensions. And just as the construction and design principles of aircraft look alien relative to the architecture of biological creatures, we should expect the design of highly capable AI systems to be quite alien when compared to the architecture of the human mind.↩
- Trying to give some formal content to these attempts to differentiate task-like goals from open-ended goals is one way of generating open research problems. In the “Alignment for Advanced Machine Learning Systems”研亚博体育官网究建议,正式化“不要太努力”的问题是轻度优化, “steer clear of absurd strategies” is保守主义, and “don’t have large unanticipated consequences” isimpact measures。See also “avoiding negative side effects” in Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané’s “AI安全中的具体问题。”↩
- 在过去的几十年中,我们在机器视觉领域中学到的一件事是,手工指定猫的外观是没有希望的,但是指定可以学习识别猫的学习系统并不难。亚博体育苹果app官方下载可以手工指定我们重视的所有内容更加绝望,但是我们可以指定一个可以学习相关的“价值”概念的学习系统是合理的。亚博体育苹果app官方下载↩
- 看 ”环境目标,”“”低影响力的代理,” and “Mild Optimization” for examples of obstacles to specifying physical goals without causing catastrophic side-effects.
Roughly speaking, MIRI’s focus is on research directions that seem likely to help us conceptually understand how to do AI alignment in principle, so we’re fundamentally less confused about the kind of work that’s likely to be needed.
What do I mean by this? Let’s say that we’re trying to develop a new chess-playing programs. Do we understand the problem well enough that we could solve it if someone handed us an arbitrarily large computer? Yes: We make the whole search tree, backtrack, see whether white has a winning move.
如果我们不知道如何回答这个问题with an arbitrarily large computer, then this would suggest that we were fundamentally confused about chess in some way. We’d either be missing the search-tree data structure or the backtracking algorithm, or we’d be missing some understanding of how chess works.
This was the position we were in regarding chess prior to Claude Shannon’s seminal paper, and it’s the position we’re currently in regarding many problems in AI alignment. No matter how large a computer you hand me, I could not make a smarter-than-human AI system that performs even a very simple limited-scope task (e.g., “put a strawberry on a plate without producing any catastrophic side-effects”) or achieves even a very simple open-ended goal (e.g., “maximize the amount of diamond in the universe”).
If I didn’t have any particular goal in mind for the system, Icouldwrite a program (assuming an arbitrarily large computer) that strongly optimized the future in an undirected way, using a formalism likeaixi。In that sense we’re less obviously confused about capabilities than about alignment, even though we’re still missing a lot of pieces of the puzzle on the practical capabilities front.
Similarly, we do know how to leverage a powerful function optimizer to mine bitcoin or prove theorems. But we don’t know how to (safely) do the kind of prediction and policy search tasks I described in the “fill a cauldron” section, even for modest goals in the physical world.
Our goal is to develop and formalize basic approaches and ways of thinking about the alignment problem, so that our engineering decisions don’t end up depending on sophisticated and clever-sounding verbal arguments that turn out to be subtly mistaken. Simplifications like “what if we weren’t worried about resource constraints?” and “what if we were trying to achieve a much simpler goal?” are a good place to start breaking down the problem into manageable pieces. For more on this methodology, see “MIRI’s Approach。”↩
- “Fill this cauldron without being too clever about it or working too hard or having any negative consequences I’m not anticipating” is a rough example of a goal that’s intuitively limited in scope. The things we actually want to use smarter-than-human AI for are obviously more ambitious than that, but we’d still want to begin with various limited-scope tasks rather than open-ended goals.
Asimov’s Three Laws of Robotics make for good stories partly for the same reasons they’re unhelpful from a research perspective. The hard task of turning a moral precept into lines of code is hidden behind phrasings like “[don’t,] through inaction, allow a human being to come to harm.” If one followed a rule like that strictly, the result would be massively disruptive, as AI systems would need to systematically intervene to prevent即使是最小的危害的最小风险; and if the intent is that one follow the rule loosely, then all the work is being done by the human sensibilities and intuitions that tell us何时以及如何应用规则。
A common response here is that vague natural-language instruction is sufficient, because smarter-than-human AI systems are likely to be capable of natural language comprehension. However, this is eliding the distinction between the system’s objective function and its model of the world. A system acting in an environment containing humans may learn a world-model that has lots of information about human language and concepts, which the system can then use to achieve its objective function; but this fact doesn’t imply that any of the information about human language and concepts will “leak out” and alter the system’s objective function directly.
Some kind of value learning process needs to be defined where the objective function itself improves with new information. This is a tricky task because there aren’t known (scalable) metrics or criteria for value learning in the way that there are for conventional learning.
If a system’s world-model is accurate in training environments but fails in the real world, then this is likely to result in lower scores on its objective function — the system itself has an incentive to improve. The severity of accidents is also likelier to be self-limiting in this case, since false beliefs limit a system’s ability to effectively pursue strategies.
In contrast, if a system’s value learning process results in a that matches our in training but diverges from in the real world, then the system’s will obviously not penalize it for optimizing . The system has no incentive relative to to “correct” divergences between and , if the value learning process is initially flawed. And accident risk is larger in this case, since a mismatch between and doesn’t necessarily place any limits on the system’s instrumental effectiveness at coming up with effective and creative strategies for achieving .
问题是三倍:
1. “Do What I Mean” is an informal idea, and even if we knew how to build a smarter-than-human AI system, we wouldn’t know how to precisely specify this idea in lines of code.
2. If doing what we actually mean is instrumentally useful for achieving a particular objective, then a sufficiently capable system may learn how to do this, and may act accordingly so long as doing so is useful for its objective. But as systems become more capable, they are likely to find creative new ways to achieve the same objectives, and there is no obvious way to get an assurance that “doing what I mean” will continue to be instrumentally useful indefinitely.
3. If we use value learning to refine a system’s goals over time based on training data that appears to be guiding the system toward a that inherently values doing what we mean, it is likely that the system will actually end up zeroing in on a that approximately does what we mean during training but catastrophically diverges in some difficult-to-anticipate contexts. See “Goodhart’s Curse”有关此的更多信息。
For examples of problems faced by existing techniques for learning goals and facts, such as reinforcement learning, see “使用机器学习来解决AI风险。”↩
- The result will probably not be a particularly human-like design, since so many complex historical contingencies were involved in our evolution. The result will also be able to benefit from a number of largesoftware and hardware advantages。↩
- This concept is sometimes lumped into the “transparency” category, but standard algorithmic transparency research isn’t really addressing this particular problem. A better term for what I have in mind here is “understanding。” What we want is to gain deeper and broader insights into the kind of cognitive work the system is doing and how this work relates to the system’s objectives or optimization targets, to provide a conceptual lens with which to make sense of the hands-on engineering work.↩
- We could选择to program the system to tire, but we don’t have to. In principle, one could program a broom that only ever finds and executes actions that optimize the fullness of the cauldron. Improving the system’s ability to efficiently find high-scoring actions (in general, or relative to a particular scoring rule) doesn’t in itself change the scoring rule it’s using to evaluate actions.↩
- We can imagine the latter case resulting in afeedback loopas the system’s design improvements allow it to come up with further design improvements, until all the low-hanging fruit is exhausted.
另一个重要的考虑因素是,对人类进行更快的科学研究的两个主要瓶颈是培训时间和沟通带宽。亚博体育官网如果我们能在十分钟之内训练新思想,成为一名尖端的科学家,如果科学家几乎可以将他们的经验,知识,概念,想法和直觉交易给其合作者,那么科学进步就可以继续进行。更快。这些类型的瓶颈正是这种瓶颈,即使在硬件或算法中没有很大的优势,也可能会使自动创新者在人类创新者上具有巨大的优势。↩
- 具体来说,火箭更广泛的经验temperatures and pressures, traverse those ranges more rapidly, and are also packed more fully with explosives.↩
- Consider Bird and Layzell’sexampleof a very simple genetic algorithm that was tasked with evolving an oscillating circuit. Bird and Layzell were astonished to find that the algorithm made no use of the capacitor on the chip; instead, it had repurposed the circuit tracks on the motherboard as a radio to replay the oscillating signal from the test device back to the test device.
This was not a very smart program. This is just using hill climbing on a very small solution space. In spite of this, the solution turned out to be outside the space of solutions the programmers were themselves visualizing. In a computer simulation, this algorithm might have behaved as intended, but the actual solution space in the real world was wider than that, allowing hardware-level interventions.
In the case of an intelligent system that’s significantly smarter than humans on whatever axes you’re measuring, you should by default expect the system to push toward weird and creative solutions like these, and for the chosen solution to be difficult to anticipate.↩