假设你想要制造一个机器人来为你实现一些现实世界的目标——这个目标需要机器人自己学习,并找出许多你不知道的东西。1
这里有一个复杂的工程问题。但是还有一个问题,弄清楚它甚至意味着建立这样的学习代理。在物理环境中优化现实目标是什么?在广泛的条件下,它是如何工作的?
在这一系列的帖子中,我将指向四种方式别目前我们知道它是如何工作的,并且有四个领域的积极研究旨在弄清楚它。亚博体育官网
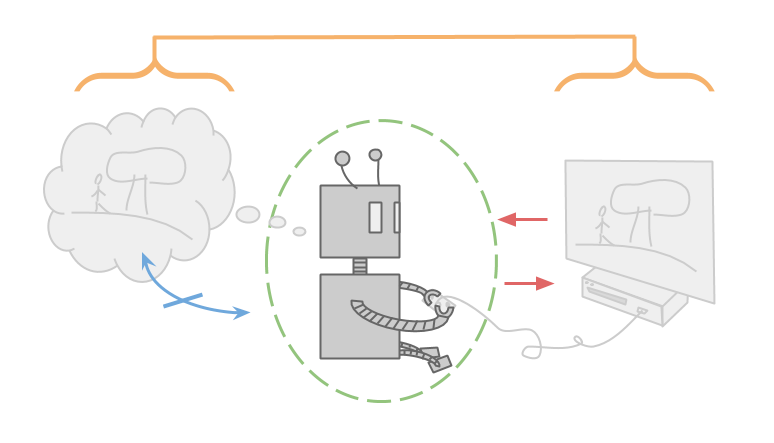
就像大多数游戏一样,这款游戏也是如此清除输入和输出通道.Alexei仅通过计算机屏幕观察游戏,只能通过控制器操纵游戏。
游戏可以被看作是一个函数,它接受一系列按键并在屏幕上输出一系列像素。
Alexei也非常聪明,并且能够在他的脑海里举行整个视频游戏.如果Alexei有任何不确定性,那么它只是他正在播放的游戏等经验事实,而不是超过哪些输入(对于给定的确定性游戏)的逻辑事实将产生它的输出。这意味着Alexei还必须在他的脑海里储存他可以玩的每一个可能的游戏。
Alexei.但是,不得不思考自己.他只是在优化他正在玩的游戏,而不是优化他用来思考游戏的大脑。他可能仍然会根据信息的价值选择行动,但这只是为了帮助他排除可能的游戏,而不是改变他的思维方式。
事实上,阿列克谢可以把自己当作一个不变的不可分割的原子.因为他并不存在于他所考虑的环境中,所以Alexei并不担心他是否会随着时间的推移而改变,也不担心他可能要运行的任何子程序。
请注意,我所谈到的所有属性之所以能够实现,部分原因在于Alexei与他正在优化的环境完全分离。
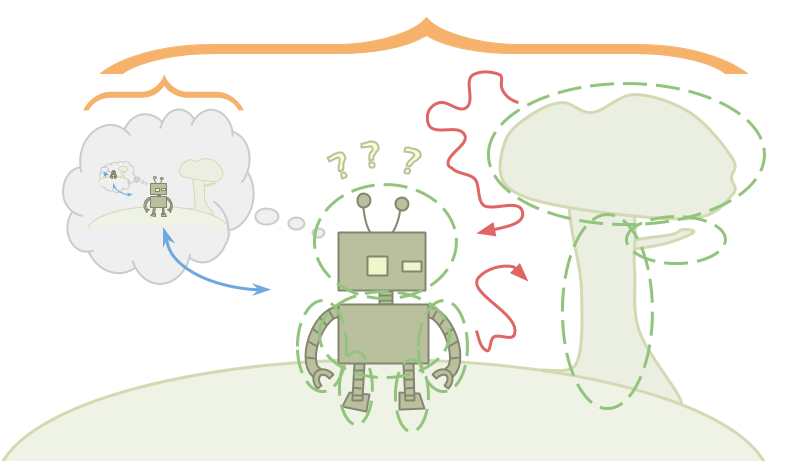
现实生活不像电子游戏。这种差异很大程度上是因为艾米处在她试图优化的环境中。
阿列克谢将宇宙视为一个函数,他通过选择能够带来比其他任何可能的输入更大回报的输入来优化这个函数。而艾米它没有功能.她只有一个环境,而这个环境包含着她。
Emmy希望选择最好的行动,但艾美的行动选择采取的行动只是关于环境的另一个事实。Emmy可以推理是她决定的环境的理由,但由于只有一个动作,艾美的目前实际上只采取了一个动作,它还不清楚Emmy甚至是什么意思是“选择”比其他人更好的行动。
Alexei可以戳宇宙,看看会发生什么。艾美是宇宙戳自己。在艾美的案例中,我们如何正式化“选择”的想法?
更糟糕的是,既然Emmy被包含在环境中,Emmy也必须被包含在环境中小于环境.这意味着Emmy无法在她的脑海中存储准确的环境的详细模型。
这就产生了一个问题:贝叶斯推理从大量的可能环境开始,当您观察到与某些环境不一致的事实时,就会将它们排除。当你甚至不能为世界的运行方式存储一个有效的假设时,推理是什么样子的呢?Emmy将不得不使用一种不同类型的推理,并做出不符合标准贝叶斯框架的更新。
由于Emmy在她操纵的环境中,她也将能够有能力自我完善.但是,艾美如何肯定会因为她学会更多并找到越来越多的方式来改善自己,她只是以实际助人的方式改变自己?她怎样才能确定她不会以不合需要的方式修改原来的目标?
最后,由于艾米被包含在环境中,她不能像对待一个原子一样对待自己。她是由同样的碎片组成环境的其余部分都是由它构成的,这就是她能够思考自己的原因。
除了外部环境的危险之外,艾米还必须担心来自内部的威胁。在优化时,Emmy可能会有意或无意地将其他优化器作为子例程来启动。如果这些子系统过于亚博体育苹果app官方下载强大,并且与Emmy的目标不一致,就会导致问题。Emmy必须弄清楚如何在不扰乱智能子系统的情况下进行推理,或者以其他方式弄清楚如何让它们变得脆弱、被控制,或者完全符合她的目标。亚博体育苹果app官方下载
艾米很困惑,我们回到阿列克谢。马库斯Hutter的AIXI框架为Alexei这样的代理如何工作提供了一个很好的理论模型:
$$
a_k \;: = \;arg \ \ max_ {a_k} \ sum_ {o_k r_k} % \ max_{现代{k + 1}} \ sum_{间{k + 1}}
\max_{a_m}\sum_{o_m r_m}
[r_k + ... + r_m]
\水平间距{1 em} \水平间距{1 em} \水平间距{1 em} \ ! \ \ ! !\sum_{{q}\,:\,U({q},{a_1..a_m})={o_1 r_1..o_m r_m}} \水平间距{1 em} \水平间距{1 em} \水平间距{1 em} \ ! \ \ ! !2 ^{\厄尔({q})}
$$
这个模型有一个代理和一个环境,可以使用行动、观察和奖励进行交互。代理发送一个动作\(a\),然后环境同时发送一个观察\(o\)和一个奖励\(r\)。这个过程每次重复\(k…m\)。
每个动作都是所有以前的动作观察奖励三元组的函数。并且每个观察和奖励类似地是这些三元组的函数和紧接在前的动作。
您可以想象这个框架中的一个代理,它完全了解与之交互的环境。而AIXI则用于环境不确定性下的优化建模。AIXI对所有可能的可计算环境都有一个分布(q\),并选择在这个分布下导致高期望回报的行为。因为它也关心未来的回报,这可能会导致对信息价值的探索。
在一些假设下,尽管有不确定性,我们可以表明AIXI在所有可计算的环境中确实很好地确实很好。但是,虽然AIXI与可计算的环境相互作用,但AIXI本身是无解扣的。代理商由不同类型的东西制成,比环境更强大的东西。
我们称像AIXI和Alexei这样的特工为“二元论”。他们存在于他们的环境之外仅在Agent-Stuff和环境之间设置交互.他们要求代理大于环境,不要倾向于模仿自我参照推理, 因为代理是由不同的材料组成的,而不是代理的推理.
艾西并不孤单。这些双重假设显示了我们目前的理性机构最佳理论。
我设置AIXI作为一个陪衬,但AIXI也可以用作灵感。当我看着AIXI的时候,我觉得我真正理解了Alexei是如何工作的。我想对艾米也有这样的理解。
不幸的是,艾米让人困惑。当我谈到“嵌入式代理”的理论时,我的意思是,我希望能够从理论上理解像艾米这样的代理是如何工作的。也就是说,嵌入在环境中的代理,因此:
- 没有明确定义的I / O频道;
- 比他们的环境小;
- 能够理解自己和自我改善;
- 由与环境相似的部件组成。
你不应该把这四个复杂的问题看成一个分割。他们彼此纠缠不清。
例如,代理能够自我改进的原因是因为它是由部件组成的。而且,只要环境比代理足够大,它就可能包含代理的其他副本,从而破坏任何定义良好的i/o通道。
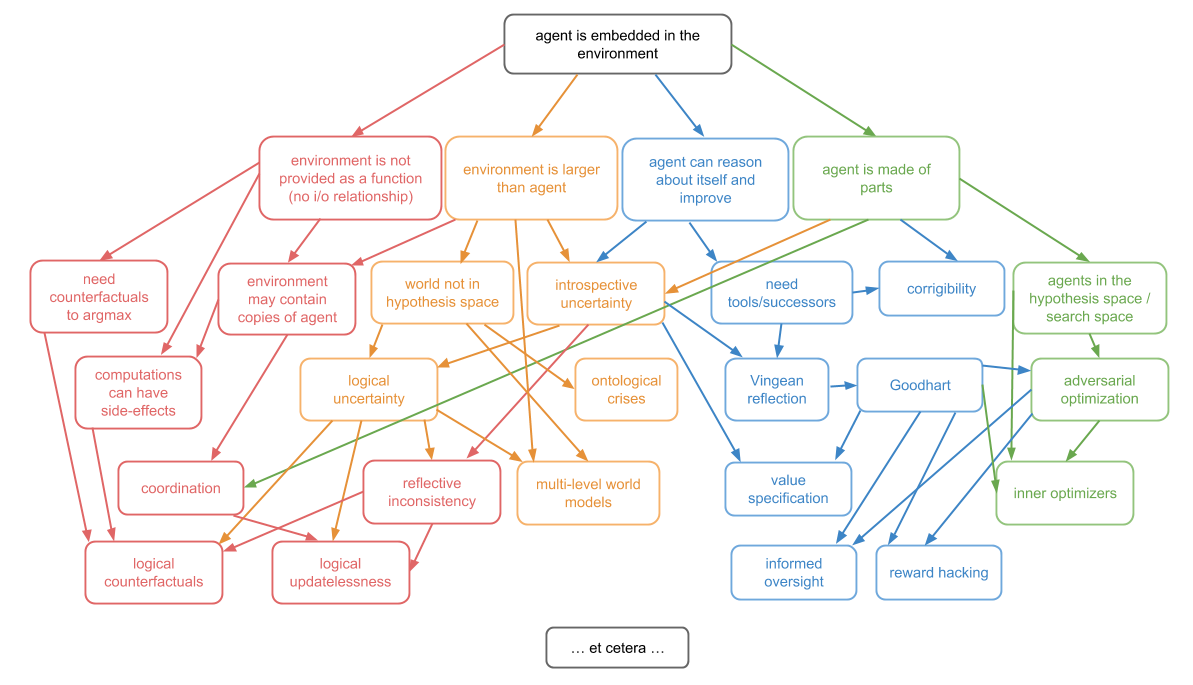
但是,我将使用这四个并发症来激发嵌入式机构主题分为四个子问题。这些是:决策理论那嵌入式世界模型那强大的代表团,子系统亚博体育苹果app官方下载对齐.
二元优化最简单的模型是\(mathm {argmax}\)。\(\ mathm {argmax}\)接受一个从动作到奖励的函数,并返回在这个函数下导致最高奖励的动作。大多数优化可以被认为是这种方法的变体。你有一些空间;你有一个从这个空间到某个分数的函数,比如奖励或效用;你想要选择一个在这个函数下得分很高的输入。
但我们刚刚说过,嵌入式代理的主要含义是你没有一个功能环境。现在我们要做什么?优化显然是代理的一个重要组成部分,但我们目前无法在不犯重大类型错误的情况下说它是什么。
决策理论中的一些主要未决问题包括:
- 逻辑反设事实你是如何推理的将如果你能采取B行动,事情就会发生证明你会采取行动A吗?
- 环境包括多个代理人的副本,或代理人可靠的预测。
- 逻辑更新,这是关于如何结合非常好的但非常贝叶斯魏代的世界不可更快的决策理论更少的逻辑不确定性的贝叶斯世界。
嵌入式世界型号是关于你如何制作世界的好模型能够适应比世界小得多的代理。
这被证明是非常困难的——首先,因为这意味着真实的宇宙并不在你的假设空间中,这就破坏了许多理论保证;第二,因为这意味着我们需要进行非贝叶斯更新也毁掉一堆理论保证。
它还涉及到如何从内部观察者的角度构建世界模型,以及由此产生的诸如人择学等问题。嵌入式世界模型中的一些主要开放问题包括:
- 逻辑的不确定性,即如何将逻辑世界与概率世界结合起来。
- 多层次的建模,关于如何在不同级别的描述中具有多种模型的多种模型,并在它们之间进行良好转换。
- 本体论的危机,当您意识到您的模型或甚至您的目标是使用不同的本体而不是现实世界指定时要做的。
强大的代表团都是关于一种特殊类型的委托代理问题。您有一个初始代理,它希望生成一个更智能的后续代理,以帮助它优化目标。最初的代理拥有所有的权力,因为它可以决定下一步的代理是什么。但在另一种意义上,继任者拥有所有的权力,因为他要聪明得多。
从最初的特工的角度来看,问题在于创建一个不会使用其情报来对付你的继任者。从后继代理的角度来看,问题是,“如何稳健地学习或尊重一些愚蠢的、可操纵的、甚至没有使用正确本体论的东西的目标?”
还有一些额外的问题Löbian障碍使它无法始终如一地信任比你更强大的事情。
您可以在刚刚学习随时间的代理人的上下文中思考这些问题,或者在代理人的上下文中制作重大自我改进的内容,或者在刚刚尝试制作强大的工具的代理人的上下文中。
强大授权的主要未决问题包括:
- Vingean反射,这是关于如何理解和信任代理商比你更聪明的代理人,尽管令霸障碍是信任的障碍。
- 价值学习,即,尽管初始代理愚蠢且不一致,但后续代理仍能了解初始代理的目标。
- 可订正这是一个关于初始代理人如何让后继代理人允许(甚至帮助)修改的问题,尽管存在不允许修改的工具激励。
子系统亚博体育苹果app官方下载对齐是关于如何成为一个统一的代理人它没有子系统和你或者其他子系统相互对抗。亚博体育苹果app官方下载
当一个代理人有一个目标,比如“拯救世界”,他可能会花大量的时间去思考一个子目标,比如“赚钱”。如果代理创建了一个只为赚钱的子代理,那么现在就会有两个具有不同目标的代理,这就会导致冲突。副代理人可能会建议看起来像他们的计划只有赚钱,但实际上摧毁了世界,以便赚更多的钱。
问题是:您不必担心您故意旋转的子代理。您也必须担心偶然旋转子药代理。随时您在能够包含代理商的足够丰富的空间上执行搜索或优化,您必须担心空间本身正在进行优化。这种优化可能不完全符合优化外部系统试图做的,但它亚博体育苹果app官方下载将有一个乐器激励看就像它对齐。
在实践中,很多优化都使用这种推卸责任的方式。你不只是找到一个解决方案;你找到了一个能够自己寻找解决方案的东西。
从理论上讲,我不知道该怎么办优化除了那些看起来像是找到一堆我不理解的东西,然后看看它是否实现了我的目标的方法。但这就是那种大多数容易造成敌对子系统的分裂。亚博体育苹果app官方下载
子系统对齐中的大开放问题是关于如何具有基本级优化器,不亚博体育苹果app官方下载会旋转对抗性优化器。通过考虑所产生的优化器所要么的情况,您可以进一步打破这个问题故意的或非故意的,以及考虑优化的受限子类,如感应.
但是请记住:决策理论、嵌入式世界模型、健壮的委托和子系统的一致性不是四个独立的问题。亚博体育苹果app官方下载它们都是同一个统一概念下的不同子问题嵌入式代理.
本文的第二部分将在接下来的几天内发布:决策理论.
你喜欢这篇文章吗?你可以享受我们的另一个yabo app 的帖子,包括: