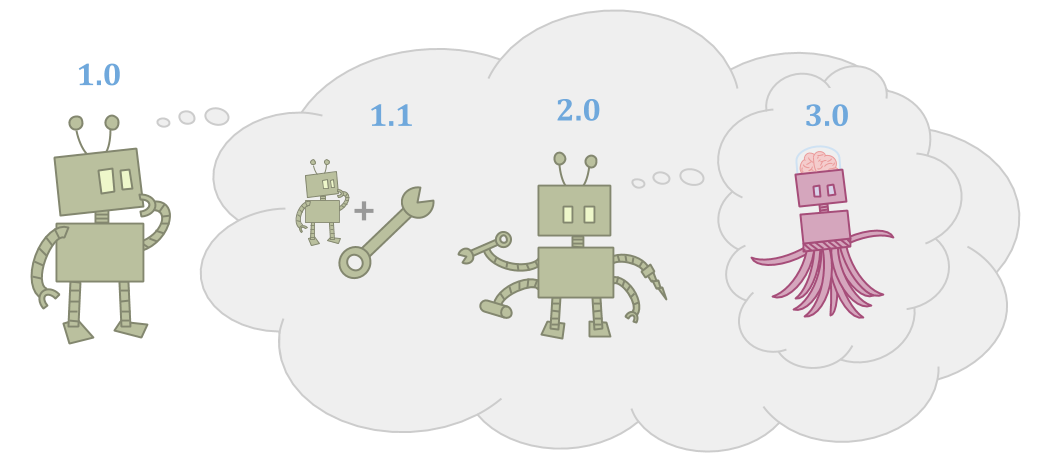
因为世界很大在这种情况下,代理人可能不足以实现其目标,包括其思考能力。
因为代理是由零件制成,它可以提高自己,变得更有能力。
改进可以采取多种形式:代理可以制作工具,代理商可以制作后继代理商,或者代理商可以学习并随着时间的推移而增长。但是,继承人或工具需要更有能力,以便值得。
这引发了一种特殊类型的主体/代理问题:
你有一个初始代理,和一个后续代理。最初的代理可以确切地决定后续代理的样子。然而,后继的代理人比最初的代理人更聪明、更强大。我们想知道如何让后继代理对初始代理的目标进行稳健优化。
以下是该校长/代理问题的三个例子可以采取:
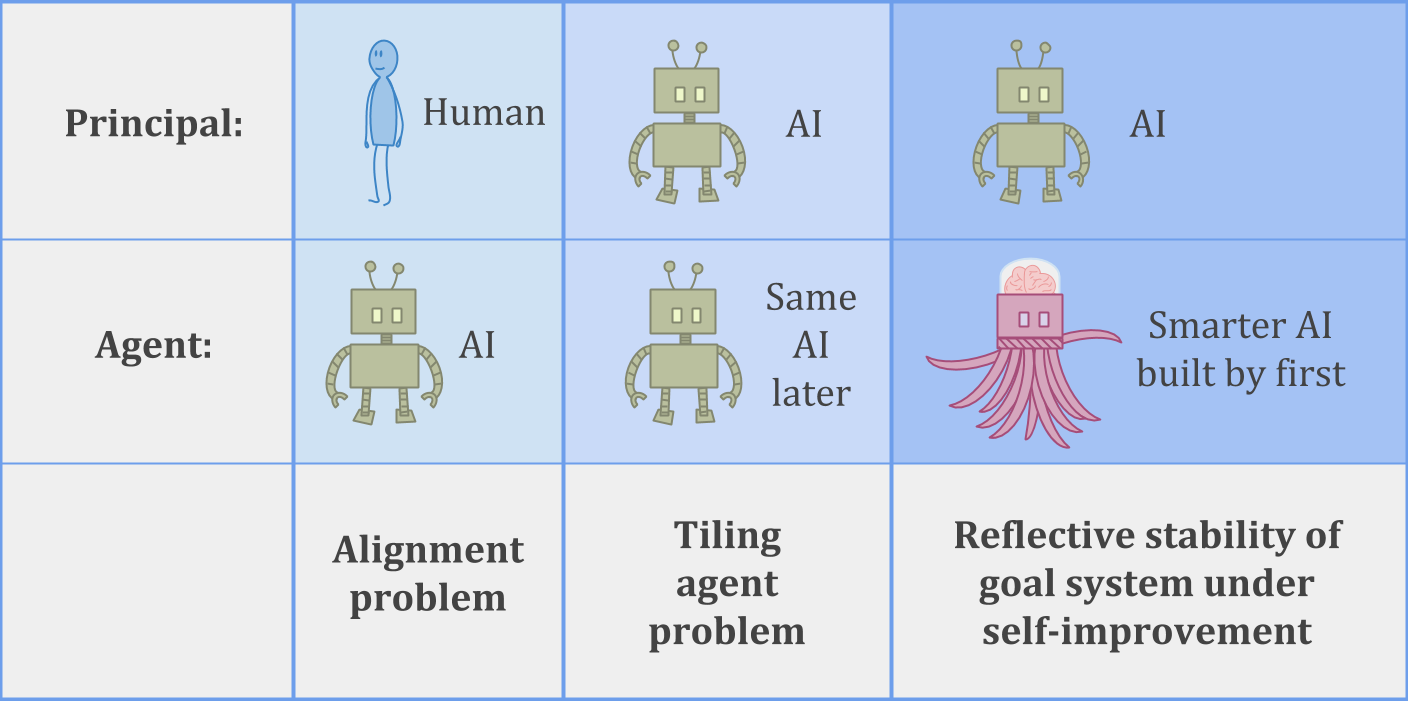
在里面AI对齐问题,人类正在努力建立一个可以信任的AI系统,可以帮助帮助人类的目标。亚博体育苹果app官方下载
在里面平铺代理问题问题,代理程序试图确保它可以相信其未来的自我来帮助自己的目标。
或者我们可以考虑一个更难的平铺问题稳定的自我改善- AI系统的位置必须建亚博体育苹果app官方下载立一个比自身更智能的继任者,同时仍然值得信赖和乐于助人。
对于一个涉及没有AI的人类类比,您可以考虑在皇室的继承问题,或者更普遍地建立组织以实现所需目标的问题,而不会随着时间的推移而忽视他们的目的。
困难似乎有两方面:
首先,人或AI代理人可能无法完全理解自己和自己的目标。如果一个代理商不能以确切的细节写出它想要的东西,这使得它很难保证其继任者会强大地帮助目标。
其次,委派工作背后的想法是你不必自己做所有的工作。您希望继承者能够以某种程度的自主行动,包括学习您不知道的新事物,并挥舞新的技能和能力。
在极限中,一个非常好的正式的正式陈述应该能够在没有呕吐的任何错误的情况下处理任意有能力的继承人,而不是建立一个令人难以置信的智能AI的错误,或者像一个只是让学习和成长为这么多的代理人多年来,它最终比过去的自我更聪明。
问题不是(只是)继任者代理可能是恶意的。问题是我们甚至不知道它意味着什么。
从这两个角度来看,这个问题似乎都很难。
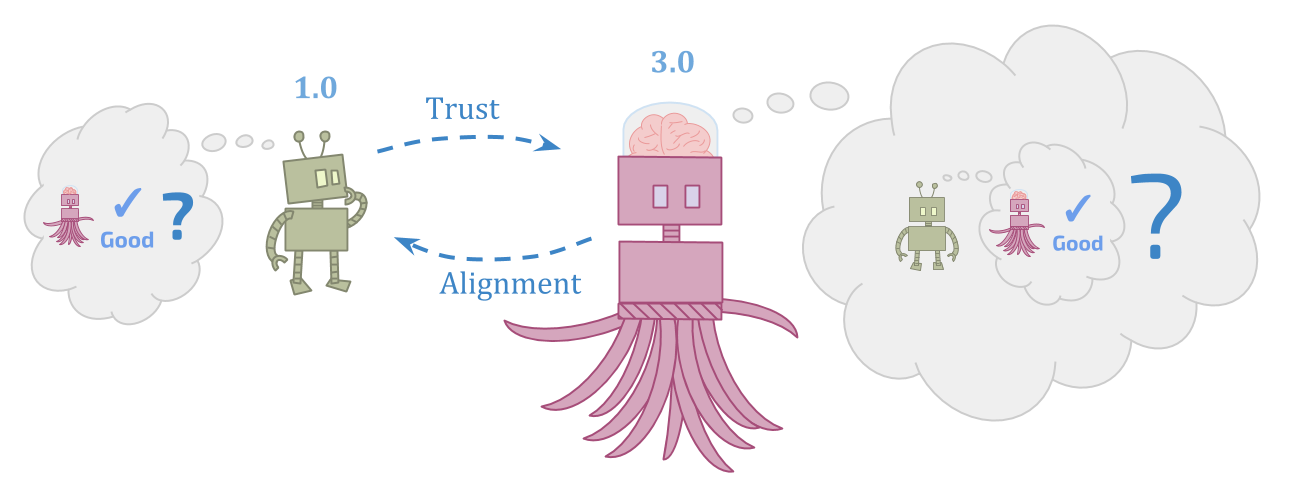
最初的代理需要弄清楚比它更强大的东西有多可靠和值得信任,这似乎很难。但后继代理必须弄清楚在最初代理甚至无法理解的情况下该怎么做,并努力尊重后继代理所能看到的目标不一致的这似乎也很难。
起初,这看起来比“做决定“ 或者 ”有模特“。但是有多种形式的“建立继任者”问题的观点本身就是一个二元化视图。
对嵌入式代理人来说,未来的自我不特权;它只是环境的另一部分。建立一个分享您的目标的后继人员之间没有深入差异,并确保您自己的目标随着时间的推移而保持相同。
所以,尽管我谈论的是“初始”和“后继”代理,但请记住,这并不只是关于人类当前在瞄准后继代理时所面临的狭窄问题。这是关于作为一个持续学习的代理的基本问题。
我们称之为这个问题强大的代表团.例子包括:
想象你在玩黄道眉鹀游戏有一个幼儿。
CIRL意味着合作逆钢筋学习。Cirl背后的想法是定义机器人与人类合作的意义。机器人试图挑选有用的行动,同时试图弄清楚人类想要什么。
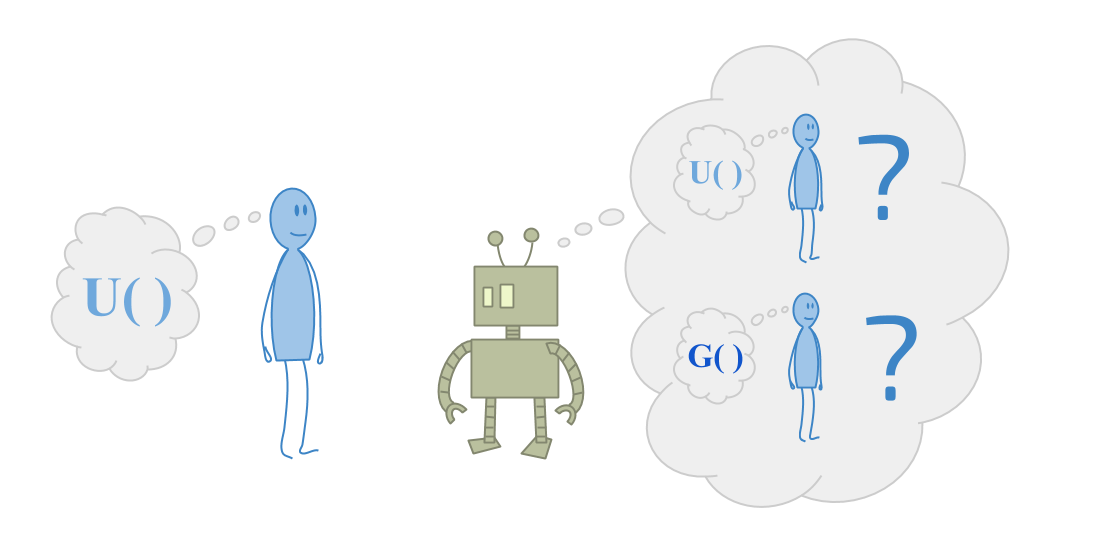
目前,许多关于健壮授权的工作都是基于将人工智能系统与人类需求保持一致的目标。亚博体育苹果app官方下载所以通常,我们从人类的角度来思考这个问题。
但现在想想智能机器人面临的问题,他们试图帮助那些对宇宙感到困惑的人。想象一下,试图帮助一个蹒跚学步的孩子优化他们的目标。
- 从你的角度来看,幼儿可能太不合理,可以被视为优化任何东西。
- 幼儿可能有一个本体论,其中它是优化的东西,但你可以看到本体没有意义。
- 也许你注意到,如果你以正确的方式设置问题,你可以让幼儿似乎几乎想要任何东西。
部分问题是“帮助”代理必须是更大的在某种意义上,为了更有能力;但这似乎暗示了“被帮助”的代理不能成为“帮手”的很好的主管。

例如,updateless决策理论消除决策理论的动态不一致,而不是最大化您行动的预期效用鉴于你所知道的,最大化预期的效用反应从一个状态到观察无知.
{kind=link}
虽然这可能是一种实现反射一致性的方法,但它在计算复杂性方面产生了一种奇怪的情况:If行动是类型\(a \),和观察类型\(o \),对观察的反应是类型\(o \ to \) - 一个更大的空间来优化超过\(a \)。我们期待着我们的小自我能够做到这一点!
这似乎是坏的。
更清晰地解决问题的方式是:我们应该相信我们未来的自我正在将其智慧应用于追求我们的目标没有能够准确预测我们未来的自己会做什么。这个准则叫做视频反思.
例如,您可以在访问新城市之前计划您的驾驶路线,但您不规划步骤。您计划对某种程度的细节,并信任您未来的自我可以弄清楚其余的。
通过古典贝叶斯决策理论,Vingean反思难以检查,因为贝叶斯决策理论假设逻辑全知.在逻辑无所不知的情况下,“agent知道自己未来的行为是理性的”这一假设等同于“agent知道自己未来的行为将根据一个特定的最优策略进行,而这个策略是agent可以提前预测的”这一假设。
我们有一些有限的Vingean反射模型(见“用于自修改人工智能的Tiling代理,以及Löbian障碍“由Yudkowsky和Herreshoff)。成功的方法必须在两个问题之间行走窄线:
- Löbian障碍:相信他们未来自我的代理商,因为他们相信自己的推理的产出不一致。
- 拖延悖论:相信他们未来自我的代理商没有理性往往是一致的,但不可靠和不可靠的,而且会永远推迟任务,因为他们可以稍后再做。
迄今为止,vingan反思的结果只适用于有限种类的决策程序,如满足者的目标是可接受的阈值。因此,在较弱的假设下,仍然有很大的改进空间,可以得到更有用的决策过程的平铺结果。
当你构建另一个代理时,而不是委派给未来的自我,你就越直接面临问题值加载.
这里的主要问题:
错误规格放大效应被称为耶和华的法律,为查尔斯古特哈特的观察命名:“一旦将压力放置在控制目的,任何观察到的统计规律都会倾向于折叠。”
当我们指定一个优化目标时,期望它与我们想要的相关是合理的——在某些情况下是高度相关的。然而,不幸的是,这并不意味着优化它就能让我们更接近我们想要的——特别是在高级优化的情况下。
(至少)四种古德哈特:回归,极值,因果和对抗性。
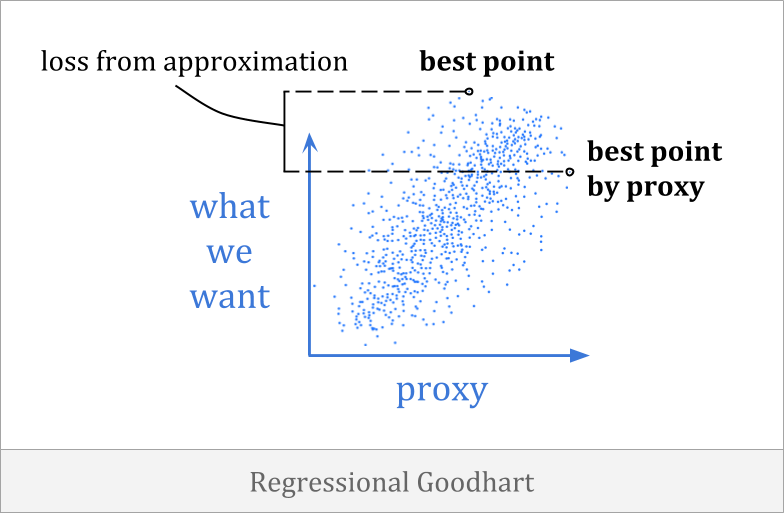
及古德哈特当代理和目标之间存在不完全相关时发生。它通常被称为优化器的诅咒,它与对均值的回归有关。
回归古德哈特的一个例子是,你可能会只根据身高来选拔篮球队的球员。这不是一个完美的启发式,但身高和篮球能力之间存在相关性,你可以利用这一点来做出选择。
事实证明,在某种意义上,如果您希望为您所选择的团队强烈持有趋势,您将被预测地失望。
用统计学的术语来说:给定\(x)的\(y)的无偏估计不是当我们选择最好的\(x)时\(y)的无偏估计。从这个意义上说,当我们使用\(x\)作为\(y\)的代理进行优化时,我们可能会失望。
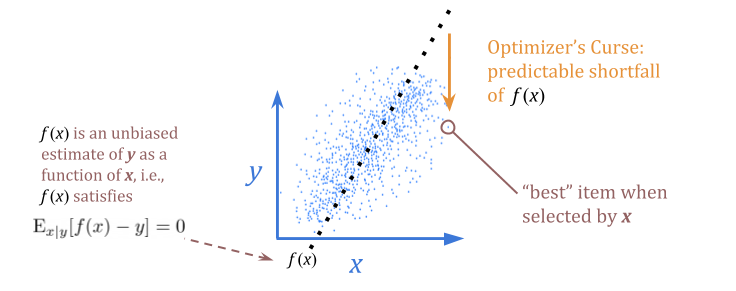
(本节中的图形是手绘以帮助说明相关概念。的)
使用贝叶斯估计而不是无偏见的估计,我们可以消除这种可预测的失望。贝叶斯估计估计\(x \)中的噪声,朝向典型的\(y \)值弯曲。
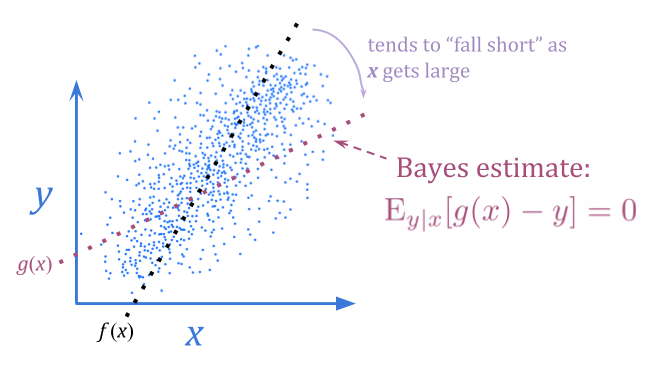
这并不一定允许我们获得更好的\(y \)值,因为我们仍然只具有\(x \)的信息内容来与之合作。但是,它有时可能会。如果\(y \)通常以方差\(1 \)分发,并且\(x \)是\(y \ pm 10 \),甚至\(+ \)或\( - \),贝叶斯估计将通过几乎完全删除噪声来提供更好的优化结果。
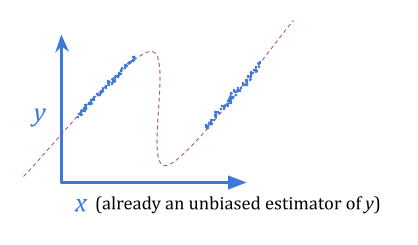
回归古德哈特似乎是最容易击败的古德哈特形式:只要使用贝叶斯!
但是,这个解决方案有两个大问题:
- 贝叶斯估算器通常在兴趣的情况下常见。
- 只有相信a下的贝叶斯估计才有意义可实现性假设。
在计算学习理论中,这两个问题都变得至关重要。
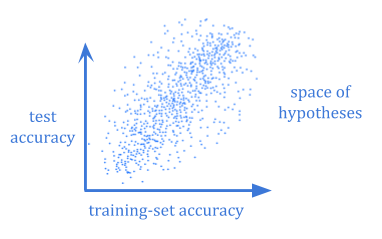
计算假设的贝叶斯预期的泛化误差通常没有计算不可行。甚至你可以,你仍然需要怀疑你的选择是否先前反映了世界。
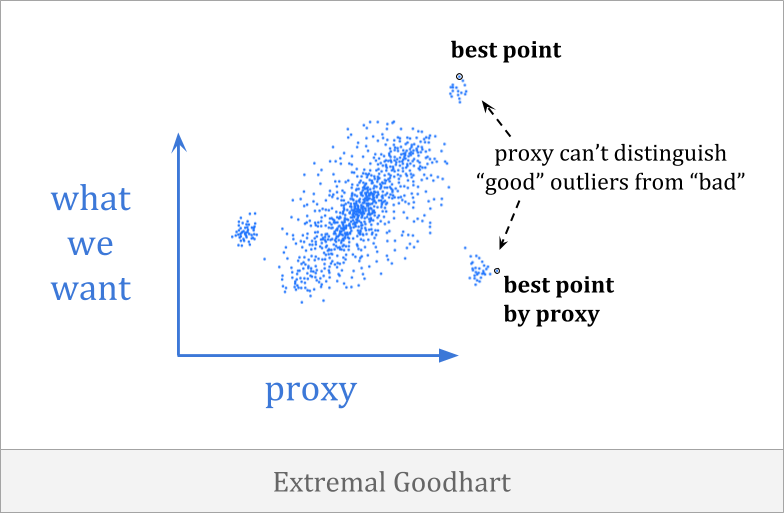
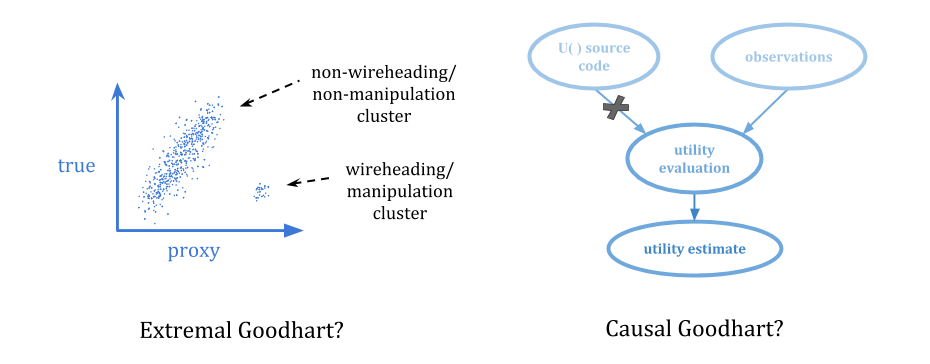
在极值古德哈特,优化将相关的范围推到相关的范围内,分为分布的分布非常不同。
这是特别可怕的,因为它往往涉及优化器在不同的环境中表现出截然不同的方式,通常很少或没有警告。在进行弱优化时,您可能根本无法观察到代理崩溃,但是一旦优化变得足够强,您就可以进入一个非常不同的领域。
极端古特哈特和回归古德哈特之间的差异与经典的插值/外推区别有关。
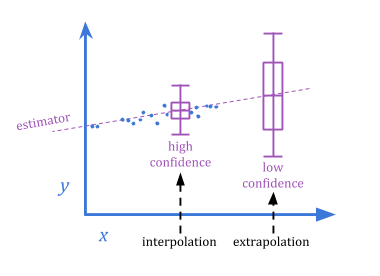
由于极值求婚涉及行为的急剧变化,因为系统被缩放,它比回归古特哈特更难预测。亚博体育苹果app官方下载
与回归案例一样,贝叶斯解决方案原则上解决了这一问题,如果您相信概率分布,以便充分利用可能的风险。然而,可实现的担忧在这里似乎更加突出。
如果这些提案高度优化以前,这些提案对该具体情况看起来很好时,可以预测建议的问题吗?当然,在这种条件下,人类的判断就无法信任 - 这一观察表明,即使系统对价值观的判断,也会留下这个问题亚博体育苹果app官方下载完美反映一个人的。
我们可能会说问题是:“典型的”输出避免极值古德哈特,但“优化太硬”将你从典型的王国中带出。
但我们如何以决策理论术语“优化太难”形式化?
量化提供了一种形式化的“优化一些,但不要优化太多”。
想象一下代理\(v(x)\)作为我们真正想要的函数的“损坏”版本,\(u(x)\)。可能有不同的地区,腐败更好或更糟。
假设我们可以另外指定一个“可信的”概率分布\(P(x)\),对此我们确信平均误差低于某个阈值\(c\)。
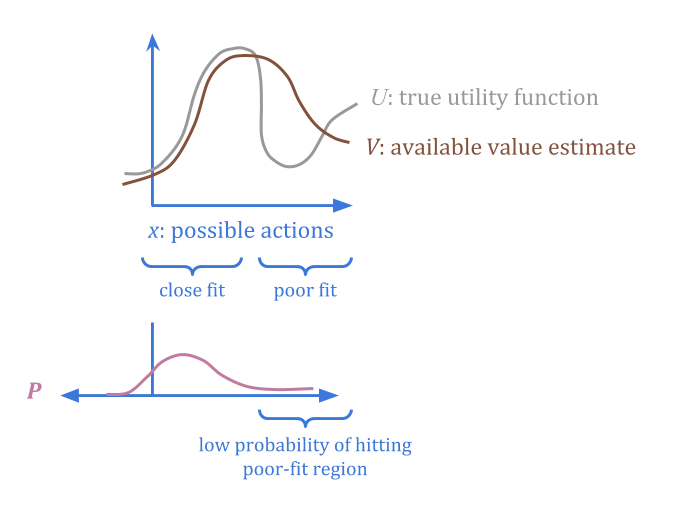
通过规定\(p \)和\(c \),我们提供有关在哪里找到低错误点的信息,而无需在任何一个点处具有任何\(u \)或实际错误的估计。
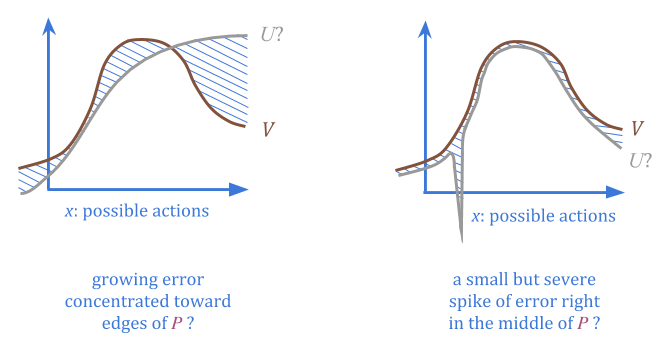
当我们随机选择从\(p \)的动作时,我们可以确定无论高误差概率都很低。
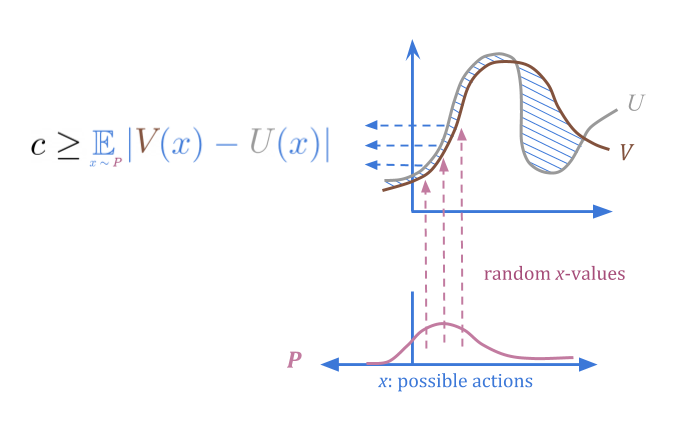
那么,我们如何使用它来优化?定量器从\(p \)中选择,但丢弃所有但顶部分数\(f \);例如,前1%。在这种可视化中,我明智地选择了一个仍然具有集中在“典型”选项上的大多数概率的部分,而不是在异常值上:
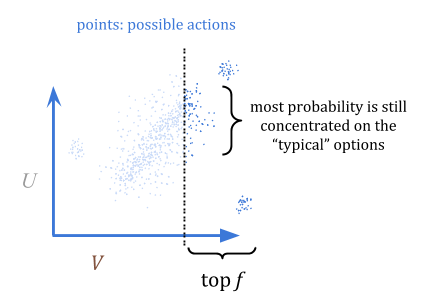
通过定量,我们可以保证,如果我们高估某种东西,我们在期望中最多\(\ frac {c} {f})。这是因为在最坏的情况下,所有的高估都是\(f \)最佳选择。
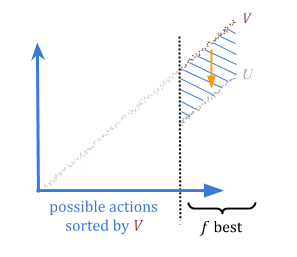
因此,我们可以选择一个可接受的风险水平,\(r = \frac{c}{f}\),并将参数\(f\)设为\(\frac{c}{r}\)。
量化在某种程度上非常有吸引力,因为它允许我们在不信任类中的每一个单独的行动 - 或不信任时指定安全的一类,而无需信任任何课堂上的个人行为。
如果你有足够大的苹果堆,并且堆中只有一个腐烂的苹果,随机选择仍然很可能是安全的。通过“优化较少的硬”并挑选随机良好的动作,我们使得非常极端的选择低概率。相比之下,如果我们尽可能努力地优化,我们可能已经最终选择了只要害群之马。
然而,这种方法也有很多不足之处。“可信的”发行版从何而来?你如何估计预期误差\(c\),或选择可接受的风险水平\(r\)?量化是一种有风险的方法,因为(r)为您提供了一个旋钮,它似乎可以提高性能,但同时增加了风险,直到(可能突然)失败。
此外,量化似乎不太可能瓷砖.也就是说,当量化代理对自身进行改进或构建新的代理时,没有特别的理由保留量化算法。
所以我们处理极端古德哈特的方式似乎还有改进的空间。
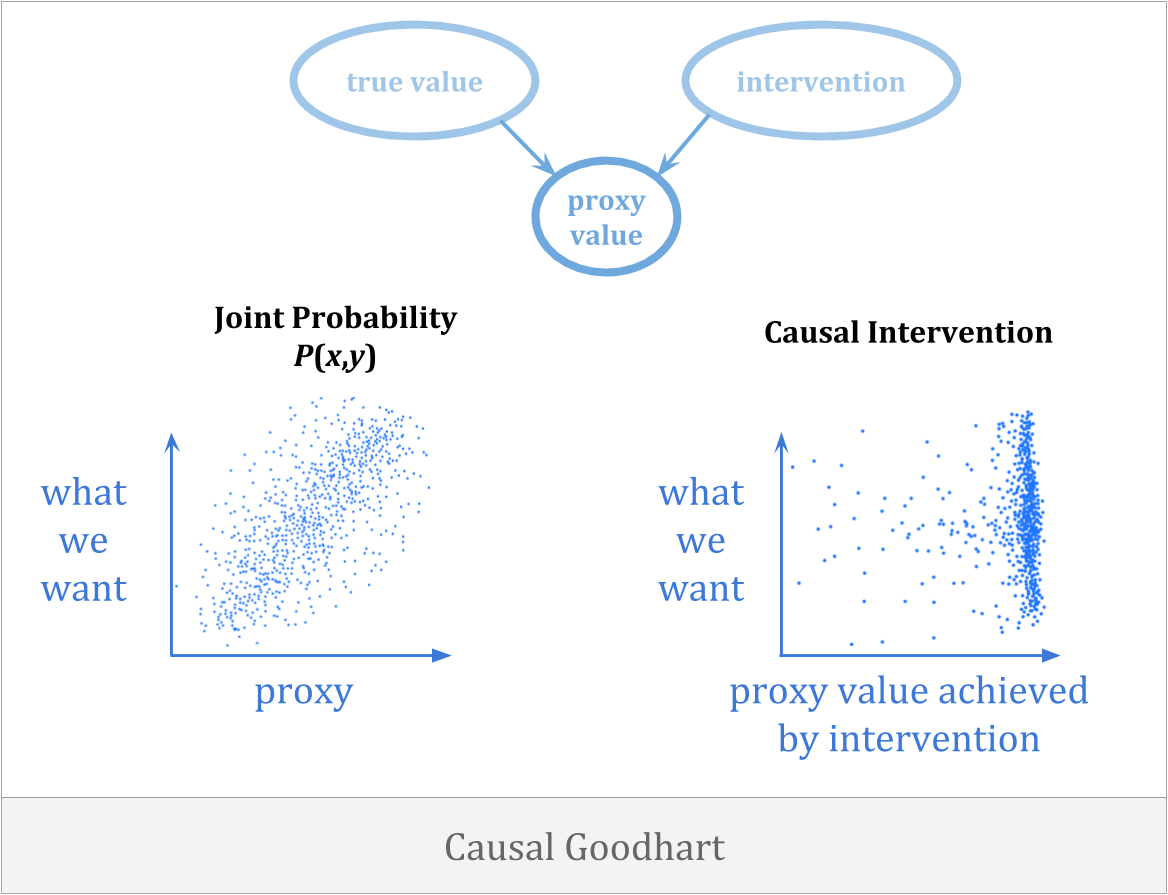
另一种优化可能出错的是,选择代理的行为打破了与我们关心的内容的连接。因果关系当您观察代理和目标之间的相关性时,但当您介入以增加代理时,您无法增加目标,因为观察到的相关性不是以正确的方式因果。
一个因果Goodhart的例子是,你可能会带着雨伞试图让天下雨。避免这种错误的唯一方法是反应性对。
这可能看起来有点像对决策理论的指责,但这里的联系丰富了强大的授权和决策理论。
反应性由于仔细顾虑令人担忧,必须解决信任的担忧 - 决策者需要理解自己的未来决定。同时,相信必须解决与事实相反的问题,因为古德哈特的原因。
再一次,这里的一个大挑战之一是可实现性.正如我们在讨论嵌入式世界模型时所指出的,即使你有正确的反事实理论,贝叶斯学习也不能保证你能很好地选择行动,除非我们假设它是可实现的。
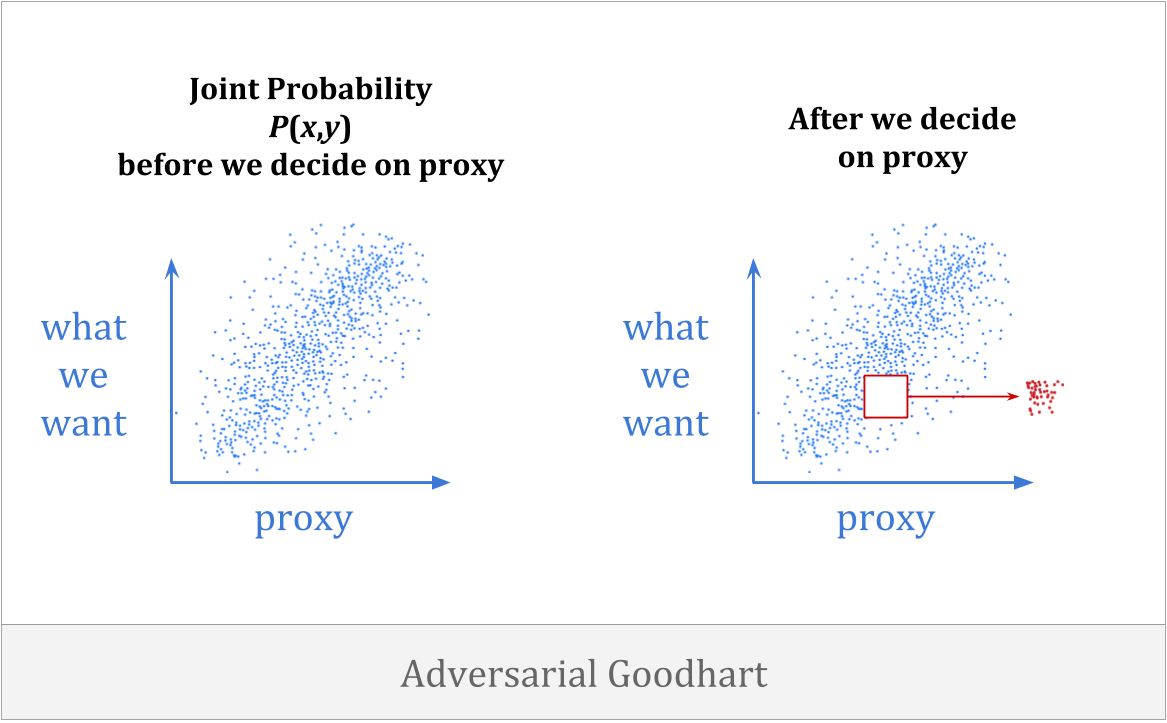
最后,有对抗性古特哈尔,在智能操纵它时,代理商正在积极地使我们的代理更糟糕。
这一类是人们在解释古德哈特的评论时最常想到的。乍一看,这似乎与我们所关注的问题无关。我们想从正式的角度理解代理人如何信任他们未来的自己,或者信任他们从零开始建立的助手。这和对手有什么关系?
简单的回答是:当在一个大足够丰富的空间,必须是这种空间的一些元素,这些空间实现了对抗性策略。了解优化一般要求我们了解足够智能的优化器可以避免对抗的优化器。(我们会在讨论中回到这一点子系统亚博体育苹果app官方下载对齐.的)
Goodhart法则的对抗变体在低优化水平上更难以观察到,因为对手在测试时间结束后才会开始操作,而且来自系统自身优化的对手在优化足够强大时才会出现。亚博体育苹果app官方下载
这四种形式的古特哈尔的法律在非常不同的方式上工作 - 粗略地说,他们倾向于开始出现在连续更高的优化力量水平上,从回归古特哈特开始并进行因果,然后是极值,然后是对抗。所以要小心不要思考你征服了古德哈尔的法律,因为你已经解决了一些人。
除了反古德哈特措施外,能够准确地说明我们想要的东西显然会有所帮助。记住,如果系统直接优化我们想要的东西,而不是优化代理,那么这些问题都不会出现。亚博体育苹果app官方下载
不幸的是,这很难。所以我们建立的AI系统可以帮亚博体育苹果app官方下载助我们吗?
更一般地说,继任者代理可以帮助其前身解决这个问题吗?也许它可以利用它的智力优势来弄清楚我们想要的东西吗?
AIXI通过从环境中获得的奖励信号来学习做什么。我们可以想象人类有一个按钮,当AIXI做他们喜欢的事情时,他们可以按下这个按钮。
问题是,艾西将把它的智能应用于控制奖励按钮的问题。这是问题线头头.
这种行为可能很难预测;系统可能亚博体育苹果app官方下载会在培训期间正如预期行为,计划在部署后控制。这被称为“奸诈扭转”。
也许我们建立奖励按钮进入代理,作为一个黑盒子,根据发生的事情来发放奖励。盒子可以是智能子委员在自己的权利中,数字化了人类想要给予的奖励。盒子甚至可以通过发布旨在修改框的行动的惩罚来保护自己。
但最终,如果代理理解这种情况,它就会有动力采取控制措施。
如果代理被告知要从“按钮”或“盒子”获得高输出,那么它就会有动机去破解这些东西。然而,如果你通过实际的奖励发放机制来运行计划的预期结果,那么破解机制的计划就会由机制本身来评估,这就不会让你觉得这个想法有吸引力。
丹尼尔·杜威称第二种特工为observation-utility达到极大.(其他人在更普遍的加强学习概念中包括观察效用代理商。)
我发现这是非常有趣的,你可以尝试各种各样的事情来阻止RL代理从窃听头,但代理一直工作反对它。然后,转向观察效用代理,问题就消失了。
但是,我们仍然存在指定\(u \)的问题。Daniel Dewey指出,观察效用代理商仍然可以随着时间的推移学习近似\(U \);我们只是不能将\(u \)视为一个黑匣子。RL代理尝试学习预测奖励功能,而观察实用程序使用估计的实用程序函数在人类指定的价值学习之前。
但是,指定一个无法导致其他问题的学习过程仍然很难。例如,如果你试图了解人类想要什么,你是如何强大的识别世界上的“人类”还仅仅统计上的物体识别可能会导致Wireheading。
即使您成功解决了该问题,代理商也可能正确地定位人类的价值,但仍可能有动力改变人类价值观更容易满足。例如,假设存在一种药物,其改变人类偏好仅仅关心使用该药物。观察效用剂可能有动力,以使人类能够更容易地实现其工作。这被称为人类操纵问题。
任何被标记为真正价值仓库的东西都会被黑。无论这是Goodharting的四种类型之一,还是第五种类型,或者它本身就是一个主题。
那么,挑战是创造稳定的指针到我们的价值:间接引用不能直接被优化的值,这不会因此鼓励破坏价值存储库。
Tom Everitt等人在"用损坏的奖励渠道加强学习:你建立反馈回路的方式会产生巨大的影响。
他们画了如下图:
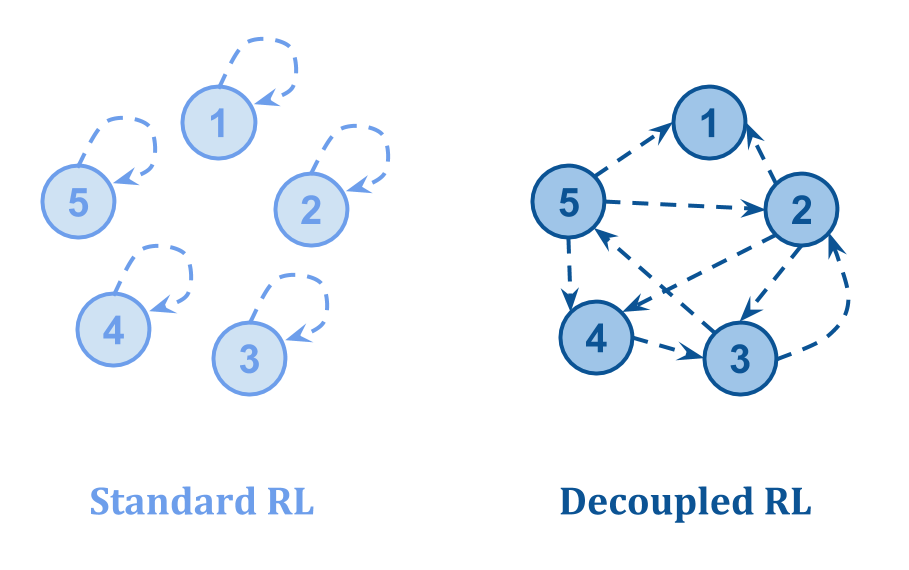
- 在Standard RL中,关于国家价值的反馈来自于国家本身,所以腐败的国家可能会“自我膨胀”。
- 在解耦RL中,关于状态质量的反馈来自于其他状态,这使得即使某些反馈被破坏了,也可以学习到正确的值。
在某种意义上,挑战是以正确的方式将原始的小代理放在反馈循环中。但是,前面提到的更可更新的推理问题使其困难;原始代理人不够。
解决这个问题的一种方法是通过智力放大:尝试将原始代理转换为具有相同值的更有能力的代理,而不是从头开始创建继承代理,并尝试加载权限。
例如,Paul Christiano提出了一种方法,其中小型代理在大树中模拟了多次,这可以通过执行复杂的计算将问题分成零件.
然而,这对小型代理来说仍然是相当苛刻的:它不仅需要知道如何将问题分解成更容易处理的部分;它还需要知道如何在不引起恶意子计算的情况下这样做。
例如,由于小代理可以使用本身的副本来获得大量的计算能力,因此很容易尝试使用Brute-Force搜索的解决方案,以实现最终运行Goodhart的法律。
此问题是下一节的主题:子系统亚博体育苹果app官方下载对齐.
你喜欢这篇文章吗?你可以享受我们的其他yabo app 帖子,包括: