决策理论和人工智能通常试图计算类似的东西
$ $ \暗流{\ \中\行动}{\ mathrm {argmax}} \ \ f (a), $ $
即,最大化动作的一些功能。这倾向于假设我们可以拆下足以将结果视为行动的函数。
例如,AIXI代表代理和环境作为通过明确定义的I / O通道随时间交互的单独单元,因此它可以选择最大化奖励的动作。
当代理模型为环境模型的一部分,可以显着不太清楚如何考虑采取替代行动。
例如,因为代理是小于环境,可以有代理的其他副本,或与代理非常相似的东西。这导致了有争议的决策理论问题,如双胞胎囚犯的困境和纽卡的问题.
如果埃米模型1和埃米模型2有相同的经验,并运行相同的源代码,埃米模型1是否应该像她的决定是在同时操纵两个机器人?根据你如何在“你自己”周围划分边界,你可能认为你可以控制两个副本的动作,或者只控制你自己的。
这是反事实推理问题的一个例子:我们如何评价像“如果太阳突然熄灭了怎么办”这样的假设?
- 反设事实
- 纽康姆式推理,即主体与自身的副本相互作用
- 更广泛地推理其他代理
- 勒索问题
- 协调问题
- 逻辑反设事实
- 逻辑updatelessness
为什么行为人需要思考反事实的最核心的例子来自于关于他们自己行为的反事实。
的困难行动反事件可以通过五到十的问题.假设我们可以选择采取五美元或十美元的账单,我们在局势中关心的就是我们得到了多少钱。显然,我们应该拿10美元。
然而,这并不是那么容易,因为它似乎可靠地接受10美元。
如果你认为自己只是环境的另一部分,那么你就能做到了解自己的行为.如果你能知道自己的行为,那么就很难去推理如果你这样做会发生什么不同的.
这将猴子扳手扔进了许多常见的推理方法。我们如何形式化“拿10美元会导致的想法”好的而拿走5美元会导致的后果坏结果,什么时候足够丰富的自我认知会揭示其中一种情况是不一致的?
如果我们不能如果把这样的想法形式化,现实世界的特工们是如何想办法拿走这10美元的呢?
如果我们试图计算贝叶斯调节我们行动的期望效用,是常见的,知道自己的行为会导致除错误当我们试图计算行为的期望效用我们知道我们不接受:\ (\ \)lnot意味着\ (P (a) = 0 \),这意味着\ (P (B \ & a) = 0 \),这意味着
$ $ P (B |) = \压裂{P (B \ & A)} {P (A)} = \压裂{0}{0}$ $
因为代理商不知道如何与环境分离,所以当它试图想象采取不同的行动时它会变得牢固的内部齿轮。
但是最大的复杂性来自Löb的定理,它可以使看起来合理的代理拿走5美元,因为“如果我拿走10美元,我得到0美元”!在一个稳定的方法——agent不能通过更多的学习或思考来解决问题。
这可能难以置信;让我们看一个详细的例子。这一现象可以用基于简单逻辑的agent对5 - 10问题进行推理的行为来说明。
考虑一下这个例子:

我们有特工和宇宙的源代码。它们可以通过使用quining互相指代。宇宙是简单的;宇宙只是输出代理输出的任何东西。
代理花了很长时间搜索有关采用各种操作的情况下会发生的证明。如果对于某些\(x \)和\(y \)等于\(0 \),\(5 \),或\(10 \),它会发现\(5 \)导致\的证据(x \)实用程序,采取\(10 \)导致\(y \)实用程序,\(x> y \),它自然会采取\(5 \)。我们预计它将无法找到这样的证据,而是选择采取\(10 \)的默认操作。
当你想象一个主体试图对宇宙进行推理时,这似乎很简单。然而,如果花费在搜索证明上的时间足够多,代理将总是选择\(5\)!
证明这一点的证据是Lob定理.Löb定理说,对于任何命题\(P\),如果你能证明a证明of (P\)表示真理取\(P\),你就可以证明\(P\)。在符号,
“\(□X\)”意思是“\(X\)是可证明的”:
$$□(□P \至P) \至□P $$
在我给出的5和10题的版本中,“\(P\)”是命题“如果代理输出\(5\)宇宙输出\(5\),如果代理输出\(10\)宇宙输出\(0)”。
假设它是可证明的,代理人最终会找到证明,并返回\(5 \)实际上。这使得这句话真正的,因为代理输出\(5\),宇宙输出\(5\),而且代理输出\(10)是假的。这是因为像“代理输出\(10\)”这样的错误命题暗示了一切,包括宇宙输出\(5\)。
代理可以(只要有足够的时间)证明所有这些,在这种情况下,代理实际上证明了命题“如果代理输出\(5\),宇宙输出\(5\),如果代理输出\(10\),宇宙输出\(0)”。结果,代理人拿走了5美元。
我们称之为“虚假证据”:代理拿走5美元,因为它可以证明这一点如果它花了10美元,它的价值很低,因为它需要5美元。这听起来像是循环,但遗憾的是,逻辑上是正确的。更一般地说,当我们在缺乏证据基础的环境中工作时,我们称之为伪造反事实的问题。
一般的模式是:反事实可能会虚假地将一个行为标记为不太好。这使得AI无法采取行动。这取决于反事实如何工作,这可能会删除任何反馈,将“纠正”有问题的反事实;或者,正如我们在基于证明的推理中看到的那样,它可能会积极地帮助虚假的反事实成为“真”。
请注意,因为基于证明的例子对我们来说意义重大,“反事实”实际上必须是计数器逻辑值;我们有时需要对逻辑上不可能的“可能性”进行推理。这排除了大多数现有的反事实推理。
你可能已经注意到我略微欺骗。唯一违反对称性并导致代理人占用5美元的事实是“\(5 \)”是当发现证据时采取的行动,“\(10 \)”是默认值。相反,我们可以考虑一个寻找任何证明的代理,了解了什么行动导致哪些实用程序,然后采取更好的行动。这样,采取了哪种行动取决于我们搜索证明的顺序。
让我们假设我们先搜索短缺。在这种情况下,我们将占用10美元,因为它非常容易显示\(a()= 5 \)导致\(u()= 5 \)和\(a()= 10 \)导致\(u()= 10 \)。
问题是,伪证据也可以很短,当宇宙变得难以预测时,也就不会再长了。如果我们用一个可以证明功能相同但更难预测的宇宙来代替宇宙,那么最短的证明将会使复杂的宇宙短路,而且是虚假的。
人们常常试图通过暗示总会有一些不确定性来解决反事实问题。AI可能很清楚自己的源代码,但它不能很清楚自己所运行的硬件。
是否添加了一些不确定性解决问题?往往不是:
- 证明杂散的反事实常常仍然通过;如果您认为您在95%确定的五十个问题中,您可以在95%内具有通常的问题。
- 增加不确定性来定义反事实并不能保证反事实会是合理的.在考虑替代操作时,硬件故障通常不是您希望看到的。
考虑一下这个场景:您确信自己几乎总是选择左边的道路。然而,有可能(虽然不大可能)对宇宙射线为了损坏您的电路,在这种情况下,您可以右转 - 但是您将是疯狂的,这将有许多其他不良后果。
如果这种推理本身这就是为什么你总是向左走,你走错了。
只需确保代理人对其行动有一些不确定性并不能确保代理人将具有远程合理的反事实预期。但是,我们可以尝试一件事是确保代理人实际上采取了每个行动有一些概率的。这个策略叫做ε探索.
ε-探索确保如果代理商在足够的场合播放类似的游戏,则可以最终学习现实的反应性(Modulo对此问题可实现性我们稍后会讲到)。
ε-探索只能有效,如果它确保代理人本身无法预测它是否即将到ε-探索。事实上,实现ε-探索的好方法是通过规则“如果代理太确定其动作,则需要一个不同的”。
从逻辑上看,ε-探测的不可预见性阻碍了我们讨论的问题。从学习理论的角度来看,如果主体知道自己不打算探索,那么它就可以将其视为一个不同的案例——未能从探索中总结教训。这让我们回到了一个情况,我们不能保证代理将学习更好的反事实。对于某些操作,探索可能是唯一的数据来源,因此我们需要迫使代理考虑这些数据,否则它可能不会学习。
然而,ε-探测似乎也不是完全正确的。通过观察ε-勘探的结果,你会发现如果你采取行动会发生什么不可预知的;作为通常的业务的一部分采取这种行动的后果可能是不同的。
假设你是一个生活在一个Ε-exporers世界的explorer。您正在申请作为保安人员的工作,您需要说服面试官,即您不是那种与您守卫的东西遇到的人。他们希望雇用一个过于诚信的人来撒谎和偷窃,即使这个人认为他们可以逃脱它。
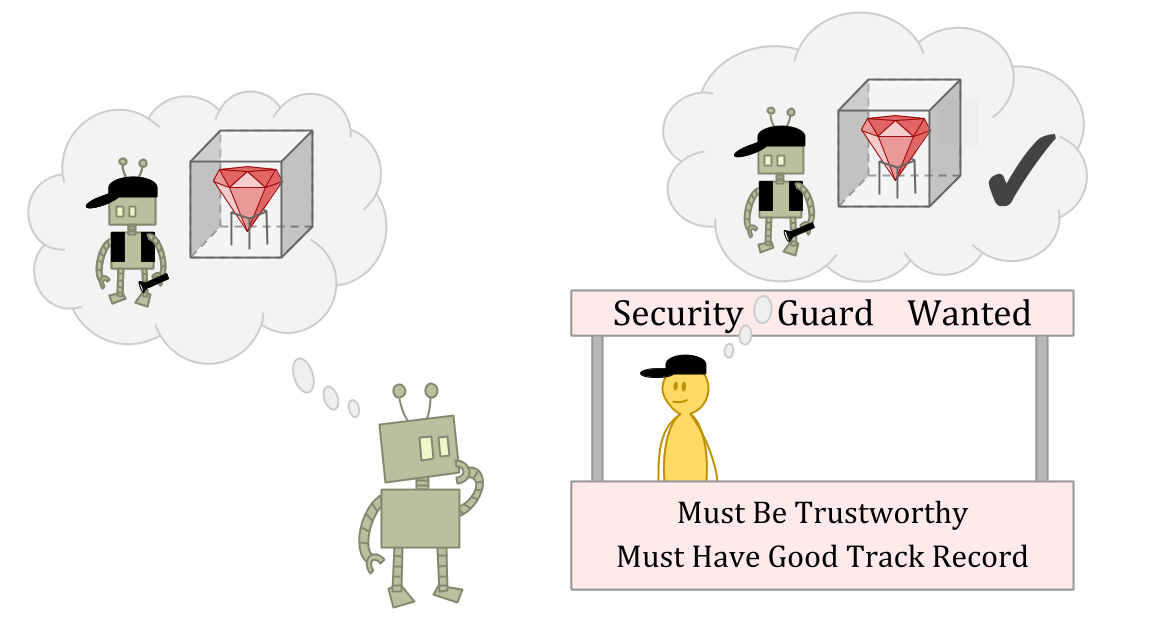
假设面试官是一个惊人的角色判断 - 或者只是读取对您的源代码的访问权限。
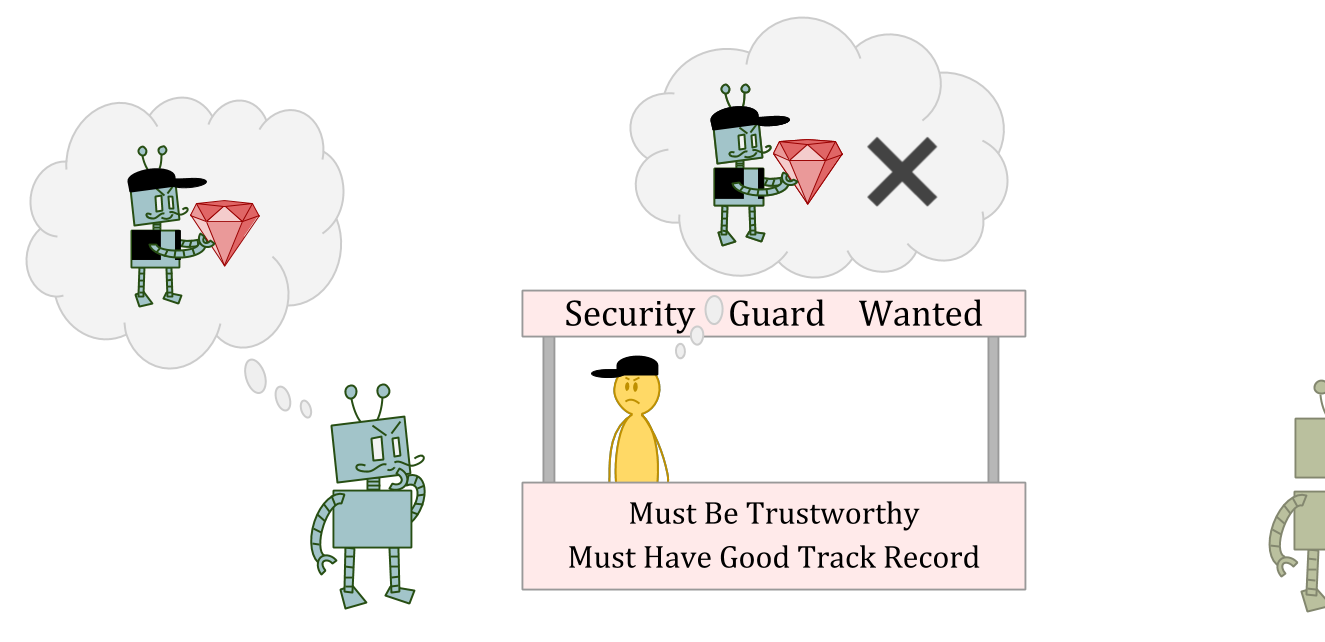
在这种情况下,偷窃可能是一个很好的选择作为ε-勘探行动,因为面试官可能无法预测你的偷窃行为,或者可能认为惩罚一次异常行为没有意义。
但是偷窃显然是一个坏主意作为一个正常的行为,因为你会被视为不那么可靠和值得信赖的人。
如果我们不能从ε-探索中学习到反事实,那么我们似乎根本无法保证学习到真实的反事实。但是,即使我们确实从ε-探测中得到了教训,似乎我们在某些情况下还是会出错。
切换到概率设置不会导致代理可靠地制作“合理”的选择,也没有强制探索。
但是从表面上看,写下“正确的”反事实推理的例子并不难!
也许那是因为从“外面”我们总是有一种二元的角度。事实上,我们坐在问题之外,我们将其定义为代理商的函数。

然而,代理不能以同样的方式从内部解决问题。从它的角度来看,它与环境的功能关系不是一个可观察到的事实。这就是为什么反事实被称为“反事实”的原因。

当我告诉你们5和10题的时候,我首先告诉你们这个问题,然后给你们一个代理。当一个代理不能很好地工作时,我们可以考虑另一个代理。
要想在决策问题上取得成功,需要找到一个代理,当插入问题时,代理会采取正确的行动。事实上,我们甚至可以考虑放入不同的主体,这意味着我们已经将宇宙划分为一个“主体”部分,再加上宇宙的其他部分中有一个主体的洞——这是我们的大部分工作!
因为我们设置决策问题的方式,我们只是在欺骗自己吗?没有“正确的”反事实吗?
好吧,也许我们是在欺骗自己。但是仍然有一些事情让我们感到困惑!"反事实是主观的,由代理人发明的"并不能解开谜团。有的东西在现实世界中,智能代理人做出决定。
所以我说的不是知道自己行为的主体因为我认为未来智能机器推断自己行为将会是一个大问题。相反,了解自己行为的可能性说明了在决定自己行为的后果时有些令人困惑的地方——这种困惑甚至出现在非常简单的情况下,即世界上的一切都是已知的,而你只需要选择一大笔钱。
尽管如此,人类拿10块钱好像没遇到什么麻烦。
我们能从人类的决策中得到启发吗?
假设你被要求在10美元和5美元之间选择。你知道你会接受这10美元。你如何推理什么将如果你花了5美元,那就发生了吗?
如果您可以将自己与世界分开,因此您似乎只想到外部后果(获得5美元)。

如果你想一下你自己同样,反事实开始显得有点奇怪或矛盾。也许你会有一些荒谬的预测,如果你拿了5美元,世界会变成什么样子,比如,“我要变成瞎子了!”
但那好了。最后,你仍然看到花费5美元会导致不良后果,你仍然需要10美元,所以你做得很好。

正式代理商所面临的挑战是一个代理可以在类似的位置,除了它是5美元,知道这是5美元,和不知道它应该花10美元相反,因为荒谬的预言就会发生什么当它需要10美元。
对于人类来说,要在这样的情况下结束似乎很难;然而,当我们试图写出一个正式的推理程序时,我们总是遇到这类问题。所以看起来人类的决策确实在做一些我们还不了解的事情。
如果你是一个嵌入式代理,那么你应该能够考虑你自己,就像你考虑环境中的其他对象一样。在你的环境中,其他理性的人也应该能够想到你。

在5和10的问题中,我们看到当主体在行动之前就知道自己的行动时事情会变得多么混乱。但这对于嵌入式代理来说是很难避免的。
特别是难以在标准贝叶斯设置中了解自己的行动,这假设逻辑不可用.概率分布将概率1赋给任何逻辑上正确的事实。如果是贝叶斯代理知道自己的源代码,那么它应该知道自己的行动。
然而,逻辑上并非无所不知的现实代理可能会遇到同样的问题。逻辑的全知推动了这个问题,但是拒绝逻辑的全知并不能消除这个问题。
ε探索做似乎在许多情况下解决了这个问题,通过确保代理对他们的选择有不确定性,并且他们期望的事情是基于经验。

但是,正如我们在保安例子中所看到的,当随机探索的结果与可靠行动的结果不一致时,ε-exploration似乎也会误导我们。
以这种方式出错的例子似乎涉及到环境的另一部分,它的行为与你类似,比如另一个与你非常相似的主体,或者一个足够好的模型或模拟你。这些被称为Newcomblike问题;一个例子是上面提到的双胞胎囚犯的困境。

如果五十岁和十个问题是关于将你形状的碎片脱离世界,以便世界可以作为你的行动的函数被视为,新的问题是关于有几个你的碎片在世界上。
一种观点是确切的在“逻辑控制”下,副本应被视为100%。对于您的近似模型,或仅仅是类似的代理,控制应急剧下降逻辑相关减少。但这是怎么做到的呢?

与迄今为止所讨论的自我参照问题一样,newcombi类问题的困难原因几乎相同:预测。通过ε-探索等策略,我们试图限制大学生的自我认识代理人为了避免麻烦。但是,环境中强大预测因素的出现再次引发了麻烦。通过选择共享什么信息,预测者可以操纵代理并为其选择行动。
如果有一些可以预测你的东西,它可能告诉你的预测,或相关信息,在这种情况下,你做什么很重要在回应对你可以找到的各种东西。
假设你决定做与别人告诉你的相反的事。那么,在一开始就不可能设置场景。要么预测者并不准确,要么预测者不跟你分享他们的预测。
另一方面,假设有一些情况,您可以如预期行事。然后,预测器可以控制您如何通过控制他们告诉您的预测来表现如何。
因此,一方面,强大的预测器可以通过在一致的可能性之间选择来控制您。另一方面,您是首先选择您的回复模式的人。这意味着您可以将其设置为您的最佳优势。
到目前为止,我们一直在讨论反事实行为——如何预测不同行为的后果。这种控制你的反应的讨论引入了观察反应性- 如果已经观察到不同的事实,那么自动化世界就是这样的。
即使没有人预测你未来的行为,观察到的反事实仍然可以在做出正确的决定时发挥作用。考虑以下游戏:
Alice以高或低的随机接收卡。如果她愿意,她可能会透露卡。然后鲍勃给出了他的概率\(p \),即爱丽丝有高卡。爱丽丝总是失去\(p ^ 2 \)美元。鲍勃失去\(p ^ 2 \)如果该卡低,并且如果卡很高,则\((1-p)^ 2 \)。
Bob有一个适当的计分规则,所以通过给出他真实的信念来做到最好。爱丽丝只是想让鲍勃的信念尽可能地“低”。
假设Alice只玩一次。她看到了一张低牌。鲍勃很擅长推理爱丽丝,但他在隔壁房间,所以看不出任何线索。爱丽丝应该出示她的卡片吗?
因为爱丽丝的牌低,如果她把牌给鲍勃,她就不会输钱,这是可能的最佳结果。然而,这意味着在反事实的世界里,爱丽丝看到一张高牌,她就不能保守秘密——在这种情况下,她可能也会把她的牌露出来,因为她不愿露出来是“高”的可靠标志。
另一方面,如果爱丽丝没有显示她的卡,她会失去25¢ - 但是她可以在其他世界中使用相同的策略,而不是失去1美元。所以,在玩游戏之前,爱丽丝希望明显承诺不透露;这使得预期损失25¢,而其他策略预计损失50美分。通过考虑意见反应性,Alice能够保密 - 没有他们,鲍勃可以完全从她的行动中推断她的卡。
这个博弈等价于决策问题叫做反事实的抢劫.
Updateless决策理论(UDT)是一个拟议的决策理论,可以保留高/低牌游戏中的秘密。UDT通过推荐代理商在做任何似乎最聪明的事情之前做到这一点早些时候的自我会承诺去做的事。
碰巧的是,UDT在newcombi类问题中也表现得很好。
像UDT这样的东西可以与人类在做什么,如果只是隐含,可以在决策问题上获得良好的结果?或者,如果不是,可能仍然是思考决策的好模式?
不幸的是,这里仍有一些非常深刻的困难。UDT是一个优雅的解决方案,对一个相当广泛的决策问题,但如果早期的自我可以预见,它只是有意义的所有可能的情况.
这在贝叶斯设置中工作得很好,因为先验已经包含了所有的可能性。然而,在现实的嵌入式设置中可能没有办法做到这一点。特工必须能思考新的可能性-这意味着它早期的自身没有足够的知识来做出所有的决定。
而且,我们发现自己正面临着这个问题嵌入式世界模型.
你喜欢这个帖子吗?你可以享受我们的另一个yabo app 的帖子,包括: