Decision theory and artificial intelligence typically try to compute something resembling
$$\underset{a \ \in \ Actions}{\mathrm{argmax}} \ \ f(a).$$
即,最大化动作的某些功能。这倾向于假设我们可以将事物弄清楚,以将结果视为动作的函数。
例如,AIXI将代理和环境表示为单独的单元,这些单元通过清晰定义的I/O频道随着时间的推移进行交互,因此它可以选择最大化奖励的动作。
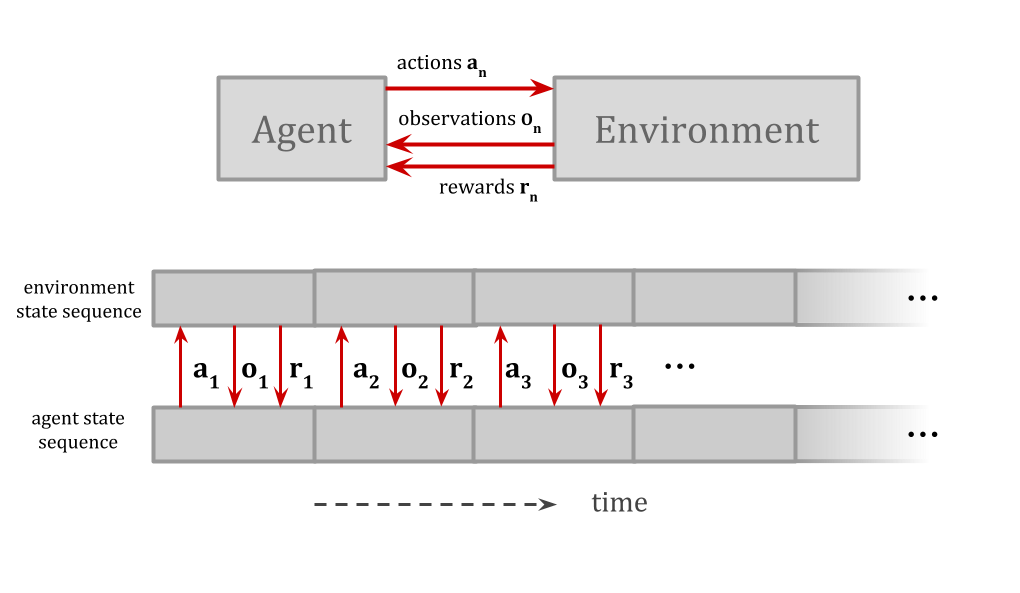
When the agent model isa part of the environment model,可能不太清楚如何考虑采取其他行动。
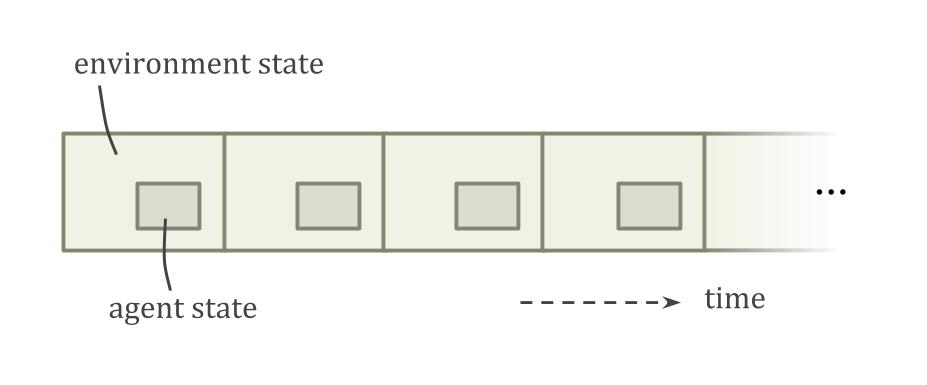
For example, because the agent issmaller than the environment, there can be other copies of the agent, or things very similar to the agent. This leads to contentious decision-theory problems such asthe Twin Prisoner’s Dilemma and Newcomb’s problem。
If Emmy Model 1 and Emmy Model 2 have had the same experiences and are running the same source code, should Emmy Model 1 act like her decisions are steering both robots at once? Depending on how you draw the boundary around “yourself”, you might think you control the action of both copies, or only your own.
This is an instance of the problem of counterfactual reasoning: how do we evaluate hypotheticals like “What if the sun suddenly went out”?
Problems of adaptingdecision theoryto embedded agents include:
- counterfactuals
- Newcomblike reasoning, in which the agent interacts with copies of itself
- reasoning about other agents more broadly
- extortion problems
- coordination problems
- logical counterfactuals
- logical updatelessness
The most central example of why agents need to think about counterfactuals comes from counterfactuals about their own actions.
The difficulty withaction counterfactualscan be illustrated by thefive-and-ten problem。假设我们可以选择收取五美元的账单或十美元的账单,而在这种情况下,我们所关心的就是我们得到多少钱。显然,我们应该花10美元。
However, it is not so easy as it seems to reliably take the $10.
If you reason about yourself as just another part of the environment, then you canknow your own behavior。If you can know your own behavior, then it becomes difficult to reason about what would happen if you behaveddifferently。
这将猴子扳手带入了许多常见的推理方法。我们如何形式化这个想法“拿10美元会导致goodconsequences, while taking the $5 would lead to坏consequences,” when sufficiently rich self-knowledge would reveal one of those scenarios as inconsistent?
And if wecan’tformalize any idea like that, how do real-world agents figure out to take the $10 anyway?
If we try to calculate the expected utility of our actions by Bayesian conditioning, as is common, knowing our own behavior leads to a divide-by-zero error when we try to calculate the expected utility of actions we know we don’t take: \(\lnot A\) implies \(P(A)=0\), which implies \(P(B \& A)=0\), which implies
$$P(B|A) = \frac{P(B \& A)}{P(A)} = \frac{0}{0}.$$
因为代理不知道如何将自己与环境区分开,所以当它试图想象采取不同的动作时,它会蒙受内部齿轮。
But the biggest complication comes from Löb’s Theorem, which can make otherwise reasonable-looking agents take the $5 because “If I take the $10, I get $0”! And in a稳定的鉴于问题不能解决the agent learning or thinking about the problem more.
This might be hard to believe; so let’s look at a detailed example. The phenomenon can be illustrated by the behavior of simple logic-based agents reasoning about the five-and-ten problem.
Consider this example:

We have the source code for an agent and the universe. They can refer to each other through the use of quining. The universe is simple; the universe just outputs whatever the agent outputs.
The agent spends a long time searching for proofs about what happens if it takes various actions. If for some \(x\) and \(y\) equal to \(0\), \(5\), or \(10\), it finds a proof that taking the \(5\) leads to \(x\) utility, that taking the \(10\) leads to \(y\) utility, and that \(x>y\), it will naturally take the \(5\). We expect that it won’t find such a proof, and will instead pick the default action of taking the \(10\).
It seems easy when you just imagine an agent trying to reason about the universe. Yet it turns out that if the amount of time spent searching for proofs is enough, the agent will always choose \(5\)!
The proof that this is so is byLöb’s theorem。Löb’s theorem says that, for any proposition \(P\), if you can prove that aproofof \(P\) would imply thetruthof \(P\), then you can prove \(P\). In symbols, with
“\(□X\)” meaning “\(X\) is provable”:
$$□(□P \to P) \to □P.$$
In the version of the five-and-ten problem I gave, “\(P\)” is the proposition “if the agent outputs \(5\) the universe outputs \(5\), and if the agent outputs \(10\) the universe outputs \(0\)”.
Supposing it is provable, the agent will eventually find the proof, and return \(5\) in fact. This makes the sentencetrue, since the agent outputs \(5\) and the universe outputs \(5\), and since it’s false that the agent outputs \(10\). This is because false propositions like “the agent outputs \(10\)” imply everything,including宇宙输出\[5 \)。
The agent can (given enough time) prove all of this, in which case the agent in fact proves the proposition “if the agent outputs \(5\) the universe outputs \(5\), and if the agent outputs \(10\) the universe outputs \(0\)”. And as a result, the agent takes the $5.
We call this a “spurious proof”: the agent takes the $5 because it can prove thatifit takes the $10 it has low value,becauseit takes the $5. It sounds circular, but sadly, is logically correct. More generally, when working in less proof-based settings, we refer to this as a problem of spurious counterfactuals.
The general pattern is: counterfactuals may spuriously mark an action as not being very good. This makes the AI not take the action. Depending on how the counterfactuals work, this may remove any feedback which would “correct” the problematic counterfactual; or, as we saw with proof-based reasoning, it may actively help the spurious counterfactual be “true”.
Note that because the proof-based examples are of significant interest to us, “counterfactuals” actually have to becounterlogicals;we sometimes need to reason about logically impossible “possibilities”. This rules out most existing accounts of counterfactual reasoning.
You may have noticed that I slightly cheated. The only thing that broke the symmetry and caused the agent to take the $5 was the fact that “\(5\)” was the action that was taken when a proof was found, and “\(10\)” was the default. We could instead consider an agent that looks for any proof at all about what actions lead to what utilities, and then takes the action that is better. This way, which action is taken is dependent on what order we search for proofs.
Let’s assume we search for short proofs first. In this case, we will take the $10, since it is very easy to show that \(A()=5\) leads to \(U()=5\) and \(A()=10\) leads to \(U()=10\).
The problem is that spurious proofs can be short too, and don’t get much longer when the universe gets harder to predict. If we replace the universe with one that is provably functionally the same, but is harder to predict, the shortest proof will short-circuit the complicated universe and be spurious.
People often try to solve the problem of counterfactuals by suggesting that there will always be some uncertainty. An AI may know its source code perfectly, but it can’t perfectly know the hardware it is running on.
Does adding a little uncertainty solve the problem? Often not:
- The proof of the spurious counterfactual often still goes through; if you think you are in a five-and-ten problem with a 95% certainty, you can have the usual problem within that 95%.
- Adding uncertainty to make counterfactuals well-defined doesn’t get you any guarantee that the counterfactuals will bereasonable。Hardware failures aren’t often what you want to expect when considering alternate actions.
Consider this scenario: You are confident that you almost always take the left path. However, it is possible (though unlikely) for acosmic rayto damage your circuits, in which case you could go right—but you would then be insane, which would have many other bad consequences.
Ifthis reasoning in itselfis why you always go left, you’ve gone wrong.
Simply ensuring that the agent has some uncertainty about its actions doesn’t ensure that the agent will have remotely reasonable counterfactual expectations. However, one thing we can try instead is to ensure the agentactually takes each actionwith some probability. This strategy is calledε-exploration。
ε-exploration ensures that if an agent plays similar games on enough occasions, it can eventually learn realistic counterfactuals (modulo a concern ofrealizabilitywhich we will get to later).
ε-exploration only works if it ensures that the agent itself can’t predict whether it is about to ε-explore. In fact, a good way to implement ε-exploration is via the rule “if the agent is too sure about its action, it takes a different one”.
From a logical perspective, the unpredictability of ε-exploration is what prevents the problems we’ve been discussing. From a learning-theoretic perspective, if the agent could know it wasn’t about to explore, then it could treat that as a different case—failing to generalize lessons from its exploration. This gets us back to a situation where we have no guarantee that the agent will learn better counterfactuals. Exploration may be the only source of data for some actions, so we need to force the agent to take that data into account, or it may not learn.
However, even ε-exploration doesn’t seem to get things exactly right. Observing the result of ε-exploration shows you what happens if you take an actionunpredictably;将该行动作为业务 - 平常的一部分的后果可能有所不同。
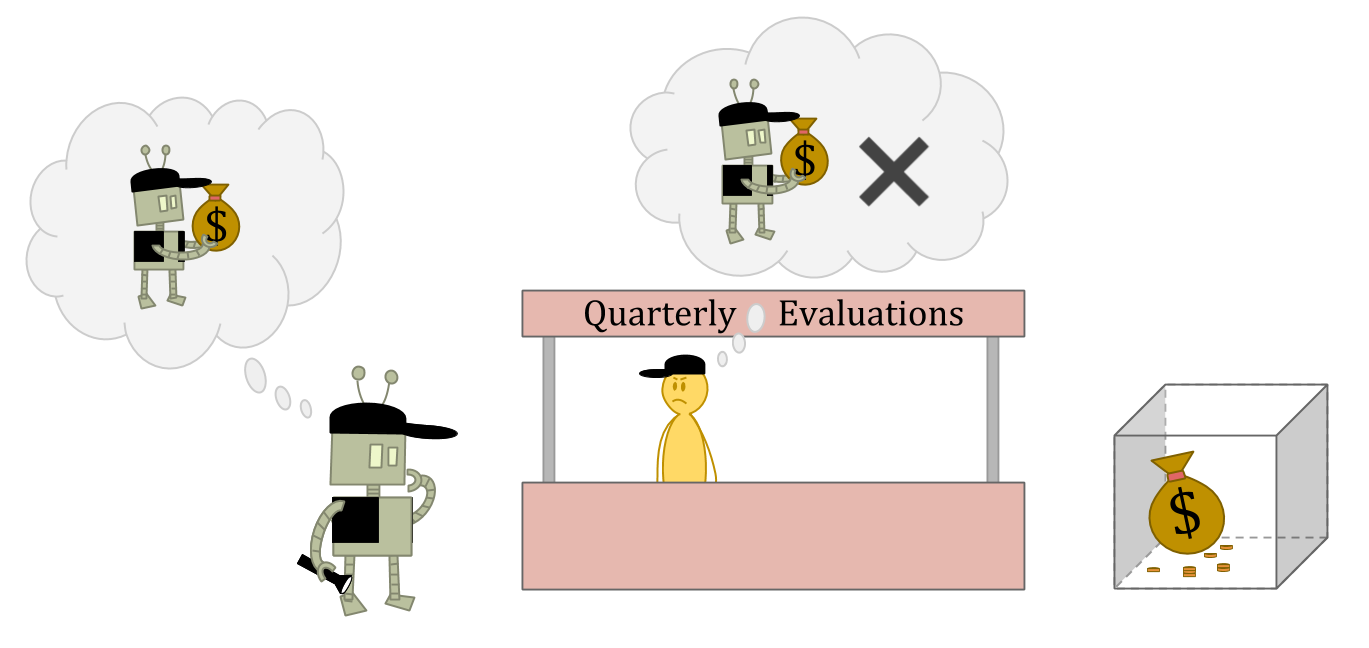
Suppose you’re an ε-explorer who lives in a world of ε-explorers. You’re applying for a job as a security guard, and you need to convince the interviewer that you’re not the kind of person who would run off with the stuff you’re guarding. They want to hire someone who has too much integrity to lie and steal, even if the person thought they could get away with it.
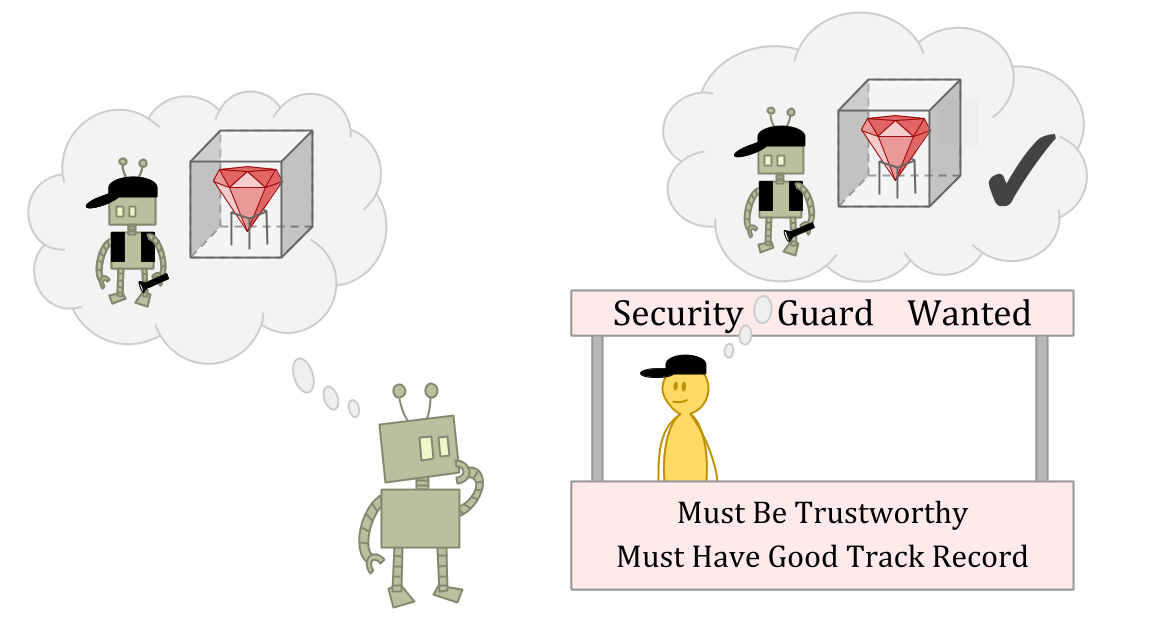
Suppose the interviewer is an amazing judge of character—or just has read access to your source code.
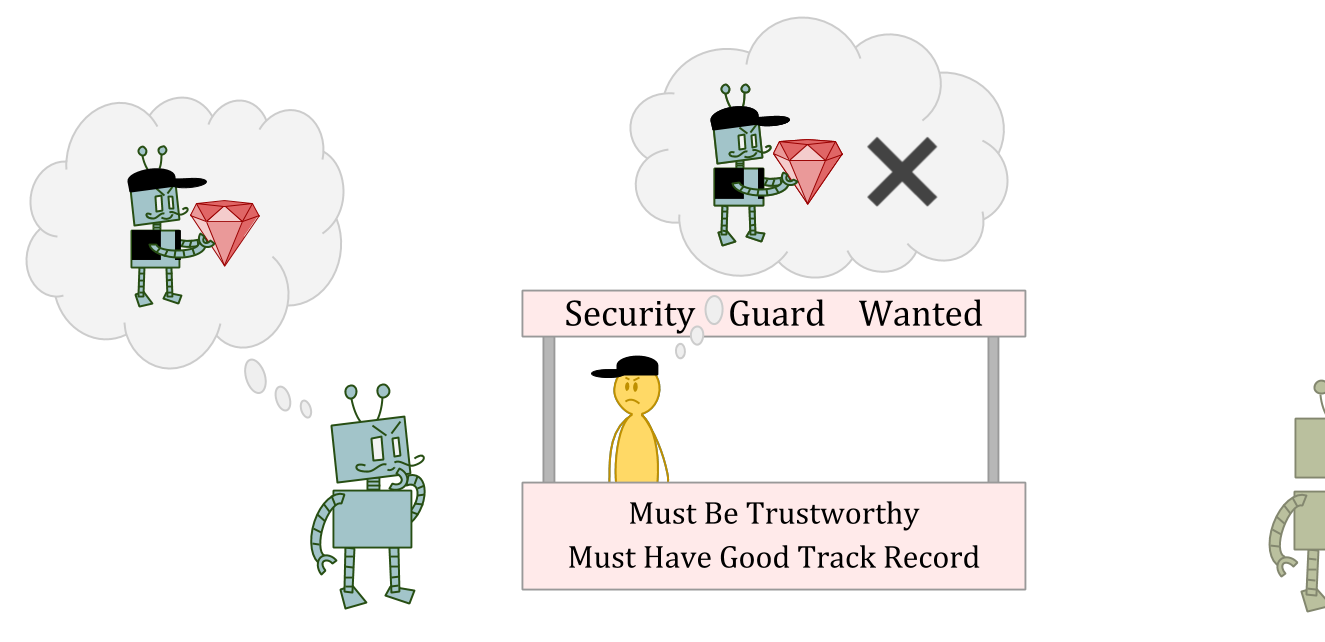
In this situation, stealing might be a great optionas an ε-exploration action, because the interviewer may not be able to predict your theft, or may not think punishment makes sense for a one-off anomaly.
But stealing is clearly a bad ideaas a normal action,因为您会被视为可靠和值得信赖。
If we don’t learn counterfactuals from ε-exploration, then, it seems we have no guarantee of learning realistic counterfactuals at all. But if we do learn from ε-exploration, it appears we still get things wrong in some cases.
Switching to a probabilistic setting doesn’t cause the agent to reliably make “reasonable” choices, and neither does forced exploration.
But writing down examples of “correct” counterfactual reasoning doesn’t seem hard from the outside!
也许是因为从“外部”中我们总是有二元论的观点。实际上,我们坐在问题之外,我们将其定义为代理的函数。

However, an agent can’t solve the problem in the same way from inside. From its perspective, its functional relationship with the environment isn’t an observable fact. This is why counterfactuals are called “counterfactuals”, after all.

When I told you about the 5 and 10 problem, I first told you about the problem, and then gave you an agent. When one agent doesn’t work well, we could consider a different agent.
Finding a way to succeed at a decision problem involves finding an agent that when plugged into the problem takes the right action. The fact that we can even consider putting in different agents means that we have already carved the universe into an “agent” part, plus the rest of the universe with a hole for the agent—which is most of the work!
Are we just fooling ourselves due to the way we set up decision problems, then? Are there no “correct” counterfactuals?
Well, maybe wearefooling ourselves. But there is still something we are confused about! “Counterfactuals are subjective, invented by the agent” doesn’t dissolve the mystery. There issomething在现实世界中,聪明的代理商确实做决定。
So I’m not talking about agents who know their own actions because I think there’s going to be a big problem with intelligent machines inferring their own actions in the future. Rather, the possibility of knowing your own actions illustrates something confusing about determining the consequences of your actions—a confusion which shows up even in the very simple case where everything about the world is known and you just need to choose the larger pile of money.
For all that,humansdon’t seem to run into any trouble taking the $10.
Can we take any inspiration from how humans make decisions?
Well, suppose you’re actually asked to choose between $10 and $5. You know that you’ll take the $10. How do you reason about whatwouldhappen if you took the $5 instead?
如果您可以将自己与世界分开,那么您只会想到外部后果(获得$ 5),这似乎很容易。

If you think aboutyourselfas well, the counterfactual starts seeming a bit more strange or contradictory. Maybe you have some absurd prediction about what the world would be like if you took the $5—like, “I’d have to be blind!”
That’s alright, though. In the end you still see that taking the $5 would lead to bad consequences, and you still take the $10, so you’re doing fine.

The challenge for formal agents is that an agent can be in a similar position, except it is taking the $5, knows it is taking the $5, and can’t figure out that it should be taking the $10 instead, because of the absurd predictions it makes about what happens when it takes the $10.
It seems hard for a human to end up in a situation like that; yet when we try to write down a formal reasoner, we keep running into this kind of problem. So it indeed seems like human decision-making is doing something here that we don’t yet understand.
If you’re an embedded agent, then you should be able to think about yourself, just like you think about other objects in the environment. And other reasoners in your environment should be able to think about you too.

In the five-and-ten problem, we saw how messy things can get when an agent knows its own action before it acts. But this is hard to avoid for an embedded agent.
尤其很难不知道自己在标准贝叶斯环境中的行动,假设逻辑无所不能。A probability distribution assigns probability 1 to any fact which is logically true. So if a Bayesian agentknows its own source code, then it should know its own action.
然而,现实的代理不是逻辑omniscient may run into the same problem. Logical omniscience forces the issue, but rejecting logical omniscience doesn’t eliminate the issue.
ε-explorationdoesseem to solve that problem in many cases, by ensuring that agents have uncertainty about their choices and that the things they expect are based on experience.

However, as we saw in the security guard example, even ε-exploration seems to steer us wrong when the results of exploring randomly differ from the results of acting reliably.
Examples which go wrong in this way seem to involve another part of the environment that behaves like you—such as another agent very similar to yourself, or a sufficiently good model or simulation of you. These are calledNewcomblike problems;一个例子是上面提到的双胞胎囚犯的困境。

如果五分四的问题是关于将世界形成的一块剪裁出来,以便将世界视为您的行动的函数,那么新康科舞会问题是关于当大约有几块形状的碎片时该怎么做在世界上。
One idea is thatexact副本应视为100%在你的“逻辑al control”. For approximate models of you, or merely similar agents, control should drop off sharply aslogical correlationdecreases. But how does this work?

Newcomblike problems are difficult for almost the same reason as the self-reference issues discussed so far: prediction. With strategies such as ε-exploration, we tried to limit the self-knowledge of theagentin an attempt to avoid trouble. But the presence of powerful predictors in the environment reintroduces the trouble. By choosing what information to share, predictors can manipulate the agent and choose their actions for them.
If there is something which can predict you, it mighttellyou its prediction, or related information, in which case it matters what you doin responseto various things you could find out.
Suppose you decide to do the opposite of whatever you’re told. Then it isn’t possible for the scenario to be set up in the first place. Either the predictor isn’t accurate after all, or alternatively, the predictor doesn’t share their prediction with you.
On the other hand, suppose there’s some situation where you do act as predicted. Then the predictor can control how you’ll behave, by controlling what prediction they tell you.
因此,一方面,强大的预测指标可以通过在一致的可能性之间进行选择来控制您。另一方面,您是首先选择您的响应模式的人。这意味着您可以将它们设置为最大的优势。
So far, we’ve been discussing action counterfactuals—how to anticipate consequences of different actions. This discussion of controlling your responses introduces theobservation counterfactual—imagining what the world would be like if different facts had been observed.
Even if there is no one telling you a prediction about your future behavior, observation counterfactuals can still play a role in making the right decision. Consider the following game:
Alice receives a card at random which is either High or Low. She may reveal the card if she wishes. Bob then gives his probability \(p\) that Alice has a high card. Alice always loses \(p^2\) dollars. Bob loses \(p^2\) if the card is low, and \((1-p)^2\) if the card is high.
Bob has a proper scoring rule, so does best by giving his true belief. Alice just wants Bob’s belief to be as much toward “low” as possible.
Suppose Alice will play only this one time. She sees a low card. Bob is good at reasoning about Alice, but is in the next room and so can’t read any tells. Should Alice reveal her card?
Since Alice’s card is low, if she shows it to Bob, she will lose no money, which is the best possible outcome. However, this means that in the counterfactual world where Alice sees a high card, she wouldn’t be able to keep the secret—she might as well show her card in that case too, since her reluctance to show it would be as reliable a sign of “high”.
另一方面,如果爱丽丝不显示她的卡,她会失去25美分,但是她可以在另一个世界中使用相同的策略,而不是损失1美元。因此,在玩游戏之前,爱丽丝想明显地承诺不透露;这使得预期损失25美分,而另一种策略预期损失50美分。通过考虑观察的反事实,爱丽丝能够保留秘密 - 鲍勃可以从自己的动作中完全推断出她的卡。
This game is equivalent to the decision problem called反事实的mugging。
Updateless decision theory(UDT)是一种建议的决策理论,可以在高/低牌游戏中保留秘密。UDT通过建议代理商做以前看起来最明智的事情来做到这一点earlier selfwould have committed to do.
As it happens, UDT also performs well in Newcomblike problems.
Could something like UDT be related to what humans are doing, if only implicitly, to get good results on decision problems? Or, if it’s not, could it still be a good model for thinking about decision-making?
Unfortunately, there are still some pretty deep difficulties here. UDT is an elegant solution to a fairly broad class of decision problems, but it only makes sense if the earlier self can foreseeall possible situations。
This works fine in a Bayesian setting where the prior already contains all possibilities within itself. However, there may be no way to do this in a realistic embedded setting. An agent has to be able to think ofnew possibilities—meaning that its earlier self doesn’t know enough to make all the decisions.
And with that, we find ourselves squarely facing the problem ofembedded world-models。
这是Abram Demski和Scott Garrabrant的一部分Embedded Agencysequence.Continued here!
Did you like this post?You may enjoy our otheryabo app posts, including: