 Erik DeBenedictis适用于Sandia的先进设备技术部门。他一直是一个成员半导体国际技术路线图自2005年以来。
Erik DeBenedictis适用于Sandia的先进设备技术部门。他一直是一个成员半导体国际技术路线图自2005年以来。
Debenedictis已收到博士学位。在CALTECH的计算机科学中。作为毕业生和后医生,他工作的硬件转向了第一个HyperCube多处理器计算机。后来被称为“Cosmic Cube,” it ran for more than a decade after he left the university and was copied over and over. It’s considered the ancestor of most of today’s supercomputers.
在20世纪80年代,在霍蒙德霍尔姆德尔的贝尔实验室工作,Debenedictis是一个联盟的一部分,该部分竞争第一个Gordon Bell奖。该团队获得了第二个地方奖,第一个去桑迪亚的地方。在20世纪90年代,他在公司开发了桌面和无线系统的信息管理软件的公司中ran Netalive。亚博体育苹果app官方下载从2002年开始,Debenedictis是其中一个项目领先的红风暴超级计算机。
埃里克表达的意见下面是他自己,而不是桑迪亚或美国能源部的意见。本文档已被桑迪亚发布为2014-2679P的沙子号码。
卢克·穆罕沃斯: Some of your work involves reversible computing, which I previouslydiscussed与迈克弗兰克。迈克的观点似乎是有希望的迹象表明可逆计算最终可能是可能的,但由于缺乏资金和感兴趣的研究人员,进展不会迅速移动。亚博体育官网是你的看法吗?并根据我对他的采访,你似乎有一个substantiallydifferent impression that Mike does about anything he and I discussed?
Erik DeBenedictis:我同意迈克,但他对由于不可逆转性的计算中的最小能量的讨论只是计算中最小能源的一部分,从而从“摩尔法结尾”开始。
For any reader who has not read Mike Frank’s interview, I’d like to give a quick summary of the relevant points. Mike was interviewed about reversible logic, which is sometimes called reversible computing. If you were a brilliant engineer and could figure out how to make a computer logic gate like AND or OR that dissipated kT joules per logic operation (the meaning of kT is in the next paragraph), you would discover that there is an additional heat production on the order of kT due to the interaction between information and thermodynamics. If you were determined to make even lower power computer gates anyway, you would have to use reversible logic principles. You could use a different universal gate set that would include a new gate such as the TOFFOLI or FREDKIN gate. You could also use regular gates (e. g. AND, OR, NOT) and a “retractile cascade” clocking scheme that reverses the computation after you capture the answer.
For reference on kT: k = 1.38 x 10-23Joules / Kelvin是Boltzmann的常数,T是T = 300个keelvin的绝对温度在室温下。Kt是约4个Zeptojoules = 4 x 10-21焦耳。将此号码与今天的计算机进行比较是不精确的,因为当今计算机中的耗散主要是归因于互连线,其长度变化。现代计算机中的AN或OR或GATE可能会消耗这一值的一百万次。
A great many respected scientists believe that reversible computing is feasible, but challenging. If their views are correct, computation should be possible at “arbitrarily low energy levels” and all theories proposing unavoidable, general limits are incorrect. There are a handful of contrary theories proposing minimum energy dissipation levels for computation. Several key ones are Landauer’s Limit of “on the order of kT” per logic operation1, a thermal limit of 40-100 kT (depending on your definition of reliable), and the concept in the popular press today that “Moore’s Law is Ending” and the minimum energy per computation is whatever is in the rightmost column of the International Technology Roadmap for Semiconductors (ITRS). That value is about 50,000 kT with typical lengths of interconnect wire.
具有多种竞争理论的科学局势可以通过科学实验来解决。例如,纽约有一个研究人员,具有在子kT范围内运行亚博体育官网的超导电路,看起来它可以展示他芯片的另一个夫妇“旋转”中的逻辑电路。展示和严格测量子KT电路将使声称不可避免的限制的所有当前理论无效。
Whether anybody will fund such an experiment should depend on whether anybody cares about the result, and I’d like to present two society-level questions that the experiment would resolve:
The computer industry started its upward trend during WWII, growing industry revenue and computer throughput in a fairly clean exponential lasting 70 years. The revenue from semiconductors and downstream industries is around $7 trillion per year right now. If there is a lower energy limit to computing, the shift in growth rate will cause a glitch in the world’s economy. My argument is that proving or disproving theories of computing limits could be accomplished for a very small fraction of $7 trillion per year.
第二个与深刻重要的计算问题有关,例如模拟全球环境,以评估气候变化问题。Petaflops超级计算机上运行的现有气候模型为未来的气候提供不同的预测,这些预测在过去十年中的观察结果分歧。无论政治如何,补救措施都是一个更复杂的气候模型,在更大的超级计算机上运行。我们不知道这方面有多较大,但在这种情况下已经提到了Zettaflops或更多。如果任何最小能量耗散理论是正确的,所需超级计算机的能量耗散可能会变得过大,气候建模可能是不可行的;如果计算在“任意低级”是真实的理论是真的,则准确的气候建模只需要高级计算机。
我试图扩大迈克的观点:对可逆计算的研究可以阐明经济的未来和地球气候,但我不知亚博体育官网道为可逆计算研究提供资金的单身人士。此外,可逆计算的结论性示范将表明有足够的空间来提高计算机效率并因此的性能。如果“Moore的法律结束”是指结束提高计算机效率的结束,验证可逆计算将显示这是一个选择不可能的问题。
卢克: From your perspective, what are the major currently-foreseeable barriers that Moore’s law might crash intobefore击中Landauer限制?(这里,我正在考虑经济上重要的“每美元计算“摩尔定律的配方而不是”串行速度“制剂,这2004年击中了一堵墙。)
Erik:有巨大的上行程序,但不一定适用于每个应用程序。The “computations per dollar” link in the question focused on the use of computers as a platform for strong Artificial Intelligence (AI), so I will comment specifically on that application: I wouldn’t be surprised to see AI accelerated by technology specifically for learning, like neural networks with specialized devices for the equivalent of synapses.
Let’s consider (a) Moore’s Law 1965 to say 2020 and (b) Beyond Moore’s Law 2020+.
从1965年到2020年,该策略是收缩线宽。这个策略将有益于1012.or so increase in computations per dollar.
我看到以下2020年的以下课程均允许每次给出10-100倍的效率增加:
- More efficient implementation of the von Neumann architecture.
- 更多的并行性,increas相称的e in the difficulty of programming.
- Software improvements for more efficient execution (e. g. new computer languages and compilers to run general code on Graphics Processing Units).
- 更好地解决较少计算的给定问题的更好算法。
- Accelerators, such as CPU+GPU today, extendable to CPU+GPU+various new accelerator types.
- Even at constant energy per gate operation, continued scaling in 2D and better use of the third dimension for reducing communications energy.
- Optical interconnect has upside, but optics is often oversold.
- Nanodevices with behavior different from a transistor that allow some computer functions to be done more efficiently. Examples: Memristors, analog components.
- 通过绝热方法,子阈值或低阈值操作或概率计算改进栅极技术。最终,可逆计算(以下注意到以下)。
- Alternative models of computation (i.e. neuromorphic) that do not use gates as normally defined.
If the ten items in the list above yield an average of 1½ orders of magnitude increase in computations per dollar each, you have more upside than the entire run of Moore’s Law.
If a couple of the items in the list don’t pan out, you could achieve excellent results by concentrating on other paths. So I do not see a general technology crash anytime soon. However, certain specific applications may be dependent on a just a subset of the list above (climate modeling was mentioned) and could be vulnerable to a limit.
可逆计算+持续降低manufacturing cost per device could extend upside potential tremendously.
但是,未来必要的技术投资将更加明确的目的。摩尔定律的信息非常简洁:行业和政府投资线宽收缩并获得了大的回报。将来,将需要许多技术投资,其目的不太清晰。
底线:一般来说,前方的路径很昂贵,但每美元计算的计算大幅增加。特定应用程序类可以看到限制,但必须具体分析它们。
卢克: What’s your opinion on whether, in the next 15 years, the黑暗的硅问题will threaten Moore’s Law (computations per dollar)?
Erik:我相信暗硅问题会对每美元的计算产生负面影响。问题和潜在的能源效率问题至少会变差,直到能量增加的成本大于精炼解决方案并将其带到生产的成本。这将最终发生,但我相信问题将持续时间比可能导致更改的势头更长。但是,当您承认有黑暗的硅问题时,您承认摩尔定律已经结束。
The underlying cause of dark silicon is that technology scales device dimensions faster than it reduces power. This causes power per unit chip area to increase, which contradicts the key statement in Gordon Moore’s 1965 paper that defined Moore’s Law: “In fact, shrinking dimensions on an integrated structure makes it possible to operate the structure at higher speed for the same power per unit area.”
The mismatched scaling rates create a problem for computations per dollar. Today, the cost of buying a computer is approximately equal to the cost of supplying it with power over its lifetime. Unless power efficiency can be increased, improvements to computer logic will not benefit the user because the amount of computation they use will be limited by the power bill.
The mismatched scaling rates can be accommodated (but not solved) by turning off transistors (dark silicon), packing microprocessors with low energy-density functions like memory (a good idea, to a point), and specialization (described in your interview under黑暗的硅问题).
The scaling rates could be brought together by more power-efficient transistors, such as the Tunnel Field Effect Transistor (TFET). However, this transistor type will only last a few generations. See这里。
理论表明每个计算的能量可以“任意小”,但研发利用这些问题将是昂贵和破坏性的。我所知道的主要方法是:
绝热。基本上不同的逻辑门电路方法。示例:mike frank的2lal。
某些低压逻辑类: For example, see CMOS LP in arXiv 1302.0244 (which is not same as ITRS CMOS LP).
Reversible computing,主题迈克弗兰克的采访。
上面的方法是破坏性的,我掩饰ve limits their popularity today. The approaches use different circuits from CMOS, which would require new design tools. New design tools would be costly to develop and would require retraining of the engineers that use them. Children learn the words “and” and “or” when they are about one year old, with these words becoming the basis of AND and OR in the universal logic basis of computers. To exploit some technologies that save computer power, you have to think in terms of a different logic basis like TOFFOLI, CNOT, and NOT. Some of the ideas above would require people to give up concepts that they learned as infants and have not had reason to question before.
卢克:当你承认有黑暗的硅问题时,你是什么意思“你承认摩尔定律已经结束了”?每百年摩尔定律至少通过2011年初举行的计算(我尚未在此之后检查数据),但自2010年以来以来,我们已经知道了黑暗的硅问题。
Erik: Moore’s Law has had multiple meanings over time, and is also part of a larger activity.
有一个非常有趣的study by Nordhausthat revealed the peak computation speed of large computers experienced an inflection point around WW II and has been on an upwards exponential ever since. Eyeballing figure 2 of his paper, I’d say the exponential trend started in 1935.
Gordon Moore published a paper in 1965 with the title “将更多组件塞到集成电路上“这包括每芯片的组件图与年份。正如我所提到的先前问题所示,本文的文本包括句子,“实际上,集成结构上的尺寸缩小尺寸使得可以以每单位面积相同的功率以更高的功率运行该结构。”图表和前一句话似乎是1974年由Dennard正式化的潜在扩展规则的主观描述,并称为Dennard缩放。
I have sketched below Moore’s graph of components as a function of year with Nordhaus’ speed as a function of year on the same axes (a reader should be able to obtain the original documents from the links above, which are more compelling than my sketch). This exercise reveals two things: (1) the one-year doubling period in Moore’s paper was too fast, and is now known to be about 18 months, and (2) that Moore’s Law is a subtrend of the growth in computers documented by Nordhaus.
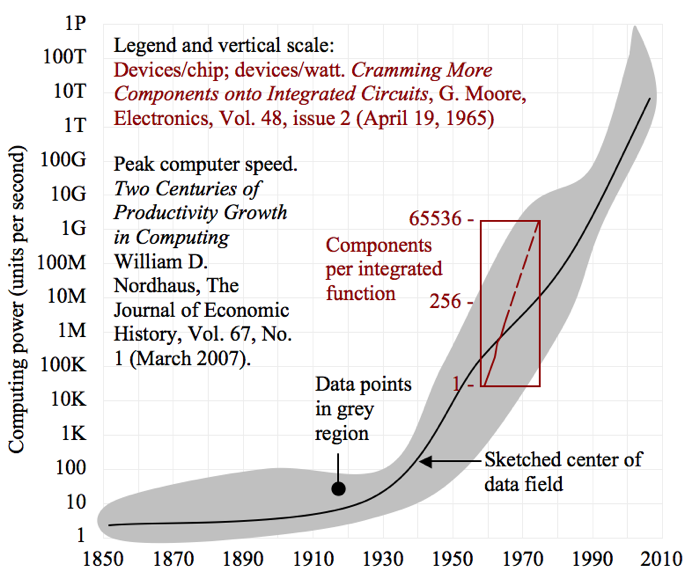
一个非常有趣的问题是摩尔是否正在申请别人的法律或两项法律是否实际上是当时未经理解的更大概念的一部分。我总结了后者。英特尔在摩尔文章后六年内没有发明微处理器。我也和人(不是摩尔)谈过的人告诉我戈登摩尔正在考虑通用电路,并没有预见微处理器的出现。
让我试着用他的论文申请摩尔定律。我记得1981年建设计算机系统,其中8086(与原始IBM亚博体育苹果app官方下载 PC中的8088非常相似)。我听说它非常复杂,消散了很多热量,所以我把手指放在它上面体验热量。我记得惊讶的是,它看起来比其他任何东西更温暖。33年后,我在去年的微处理器中思考了来自微处理器的热量。由于Moore的法律说每单位面积的电源是相同的,并且碎片几乎与1厘米的大小相同2,我应该能够把手指放在芯片上,感觉不热。现实是,坐在今天的微处理器之上有一个新的结构,让我想起了Darth Vader的头部,并被称为“散热器”。散热器是去除由芯片产生的50-200瓦的热量。我相信我刚刚做出了任何带有散热器的微处理器违反了摩尔定的案例。
What’s going on? Moore’s Law is being given additional meaning over and above what Moore was thinking. Many people believe Moore’s Law is only about dimensional scaling, a conclusion supported by the title of his article and the main graph. Moore’s Law has also been associated with computations per dollar, but that law had been around for 30 years before Moore’s paper.
I found theinterview随着哈迪Esmaeilzadeh在黑暗的硅中追踪,但他使用了对摩尔定律的另一种解释 - 摩尔定律持续的一个,但丹尼德缩放在2000年代中期结束。然而,我引用了来自Moore的论文的短语,披露了后来被称为Dennard缩放的缩放规则。
At a higher level, I believe Moore’s Law has turned into a marketing phrase that is being redefined as needed by the semiconductor industry so it remains true.
那么为什么每美元的计算上升?多年来,供应商目标是使处理器迅速运行Word处理器和Web浏览器。这一趋势在2000年代初期有高潮,与Pentium IV等处理器,带有4 GHz时钟并消散200W +。顾客反叛和行业转移到多核。通过N核微处理器,在一个核心上运行基准的结果可以乘以n。这是第2项在我对先前问题的回答(更平行的情况下,在编程中的困难时)的响应的一个例子。即使是现在,大多数软件也没有利用多个核心。
卢克: You write that “Customers rebelled and industry shifted to multicore.” I typically hear a different story about the 2002-2006 era, one that didn’t have much to do with customer rebellion, but instead the realization by industry that the quickest way to keep up the Moorean trend — to which consumers and manufacturers had become accustomed — was to jump to multicore. That’s the story I see in e.g.The Future of Computing Performanceby National Academies Press (official summary这里). Moreover, the power scaling challenge to Moore’s Law was anticipated many years in advance by the industry,例如在ITRS报告中。你能澄清你的意思是“拒绝的客户反叛”?
Erik: What happens if you take projections of the future to be true and then the projections change? You eventually end up with multiple “truths” about the same thing in the historical record. I accept that the stories you hear are true, but there is another truth based on different projections.
让我们在数学上颠覆ITRS路线图,看看当今(2014)微处理器时钟速率的预测如何发展为行业寻址的电力缩放并转移到多核。我回去了earlier editions of the ITRSand accessed edition reports for 2003, 2005, and 2007. In table 4 of the executive summary of each edition, they have a projection of “on chip local clock,” which means microprocessor clock rate. I accessedPricewatch获得2014时钟速率。
| On chip local clock | In year 2013 | In year 2014 | In year 2015 |
| 投影2003年ITRS | 22。9 GHzTable 4c | 在本版中唯一的奇数岁月 | 33.4 GHZTABLE 4D |
| 2005年ITRS投影 | 28.4 GHZTABLE 4D | ||
| Projection in 2007 ITRS | 7.91 GHZTABLE 4C. | ||
| 2014现实 | 4.0 GHz pricewatch.com. |
最显着的问题是2003年和2005年版本夸大了速度约为7倍。ITRS于2007年收纳到多芯,并以新的缩放模型在回想表中看到的是仅仅2倍的现实。2007年ITRS中的脚注1描述了变化。脚注以下列句子结束:“这是为了反映最近的片上频率减慢趋势和预期的速度 - 功率设计权衡,以管理最多200瓦/芯片经济实惠的电源管理权衡。”
如果您认为ITRS是“行业”,而且在行业一直告诉客户通过上升时钟率来期待摩尔定律的利益。在我的观点中,客户率先说,即使它意味着使用并行编程模型也是更难的情况下,每个芯片的电源也应小于200瓦。多年来多年来,多士成为流行的流行,产业改变了投影,因此客户需要通过每美元计算而不是速度来期待进步的益处。当然,这导致了电池电量的升高,电源限制远低于200瓦。
By the way, I have not heard the phrase “Moorean trend” before. It seems to capture the idea of progress in computing without being tied to particular technical property. Why don’t you trademark it; it gets zero Google hits.
卢克:您是否愿意在计算中进行一些预测到下一个15年?对于以下任何一项,我会听到您的观点估计,甚至更好的70%的置信区间:
- FLOPS per US dollar in top-end supercomputing in 2030.
- Average kT per active logic gate in top-end supercomputing in 2030.
- 在2030年,可逆计算的一些特殊程度的进展情况?
- World’s total FLOPS capacity in 2030. (See这里。)
Or really, anything specific about computing you’d like to forecast for 2030.
Erik:每美元质疑的拖鞋将是最有趣的,所以我会留下它。
kT/logic op: I see a plateau around 10,000 kT, and will discuss what might come beyond the plateau in the next paragraph.. My guess of 10,000 kT includes interconnect wire, which is significant because today 75-90% of energy is attributable to interconnect wire. Today, we see around 50,000 kT. A reduction in supply voltage to .3v should be good for 10x improvement, but there are other issues. This estimate should be valid in 10 years, but the question asked about 15 years.
我们不会感到惊讶于我们在间隔2025-2030中看到一种新方法(下面提到)。将难以预测,但五年间隔是短暂的,并且改善率似乎对细节不敏感。所以说,2030年,有5倍的额外改进。
累计到2030年: 2,000 kT/logic op, including interconnect wire. However, this will be really disappointing. People will expect 10 doublings due to Moore’s Law in the 15-year interval, for an expected improvement of 1024x; I’m predicting 25x.
Reversible computing: I think reversible computing (as strictly defined) will be demonstrated in a few years and principally impact society’s thought processes. The demonstration would be computation at less than 1 kT/logic op, where theory says those levels are unachievable unless reversible computing principles are used. I do not expect reversible computing to be widely used by 2030. The projection of 2,000 kT/logic op in 2030 represents a balance of manufacturing costs and energy costs.
到2030年,可以在一些应用中使用可逆计算,其中功率非常昂贵,例如航天器或可植入的医疗设备。
However, a demonstration of reversible computing could have an important impact on societal thinking. Popular thinking sees some ideas as unlimited for planning purposes and endows those ideas with attention and investment. This applied to California real estate prices (until 2008) and Moore’s Law (until a few years ago). Claims that “Moore’s Law is Ending” are moving computation into a second class of ideas that popular thinking sees as limited, like the future growth potential of railroads. A reversible computing demonstration would move computing back to the first category and thus make more attention and capital available.
However, reversible computing is part of a continuum. I see a good possibility that adiabatic methods could become the new method mentioned above for the 2020-2025 time range.
世界总拖波能力,2030年。我看了看document by Naikyou cited. I don’t feel qualified to judge his result. However, I will stand by my ratio of 50,000 kT to 2,000 kT = 25. So my answer is to multiply Naik’s result by 25. I do not imagine that the cumulative power consumption of computers will rise substantially, particularly with Green initiatives.
每美元拖鞋:这个答案将到处都是。让我们通过应用程序类分解:
(A) Some applications are CPU-bound, meaning their performance will track changes in kT per logic op. I have given my guess of 25x improvement (which is a lot less then the 1024x that Moore’s Law would have delivered).
(b)其他应用程序是内存界限,意味着它们的性能将跟踪(a)内存子系统性能,其中由于摩尔定律和(b)架构更改,可以减少数据移动量的架构部分重叠。亚博体育苹果app官方下载
It is a lot easier to make a computer for (A) than (B); for a given cost, a computer will outperform type A applications by an order of magnitude or more on FLOPS compared to type B.
顶端超级计算机支持A和B,但A和B之间的平衡可能是时代的深刻问题。余额已经大量加权,支持(通过依赖Linpack作为基准)。但是,我们目前没有在美国拥有特别侵略性的Exascale计划。相反,我们对内存子系统的低能量效率进行了大量讨论。亚博体育苹果app官方下载您可以对最低端超级计算的进展情况进行相当令人信服的案例,直到计算机变得更好地平衡。
(对于参考,前2名超级计算机是奥斯坦特,17.5 Petaflops Linpack为9700万美元;比例为181 MFLOPS / $。前1名超级计算机似乎并不是一个很好的成本参考。)
如果架构保持固定到2030,我会猜测25倍的改进。这将是4.5 GFLOPS / $。存储器子系统由与逻辑亚博体育苹果app官方下载相同的晶体管技术制成,也许加上越来越多的光学元件。如果晶体管变得更加有效25倍,这可能会使拖鞋和存储器子系统受益。亚博体育苹果app官方下载使用3D可以提高性能(由于电线较短),但由于难以利用更大的并行性,这将抵消效率损失。打电话给后一种因素洗净。
Architecture is the wildcard. There are architectures known that are vastly more efficient than the von Neumann machine, such as systolic arrays, Processor-In-Memory (PIM), Field Programmable Gate Arrays (FPGAs) and even GPUs. These architectures get a performance boost by organizing themselves to put calculations closer to where data is stored, requiring less time and energy to complete a task. Unfortunately, these architectures succeed at the expense of generality. If a vendor boosts performance through too much specialization, they run the risk of being disqualified as an example of a “top-end supercomputer.” The Holy Grail would be a software approach that would make general software run on some specialized hardware (like a compiler that would run general C code on a GPU – at the full performance of the GPU).
但是,我将预测架构改进将额外的4x到2030,累积改善因子为100倍。这将是18 GFLOPS / $。这仍然是15年来的1024倍的10倍。
However, I think Artificial General Intelligence (AGI) may fare well due to specialization. Synaptic activity is the dominant function that enables living creatures to think, but it is quite different from the floating point in a supercomputer. A synapse performs local, slow, computations based on analog stimuli and analog learned behavior. In contrast, the floating point in a supercomputer operates blazingly fast on data fetched from a distant memory and computes an answer with 64-bit precision. Speed reduces energy efficiency, and the supercomputer doesn’t even learn. Since a von Neumann computer is Turing complete, it will be capable of executing an AGI coded in software. However, the efficiency may be low.
执行AGI可以通过新的或专业技术进行优化,并比摩尔定律的速度更快地提高,如比特币采矿。我要投入项目,即规模的AGI演示将需要非传统的,但不是不可思议的计算机。计算机可以专门的CMOS,如GPU,具有特殊数据类型和数据布局。或者,计算机可以采用新的物理设备,例如具有非晶体管器件的神经形态架构(例如,函数)。
All said, AGI might see 1000x or more improvement. In other words, AGI enthusiasts might be able to plan on 181 GFLOPS/$ by 2030. However, they would be classed as AI machines rather than top-end supercomputers.
卢克: Thanks, Erik!
- 注释在审查中添加:Landauer仅为“不可逆转”计算的“按kt阶数”提出下限。据我所知,“Landauer的极限”短语稍后由其他人创建。在我的经验中,如果通常以一般限制应用,“Landauer的极限”短语。↩
你喜欢这篇文章吗?You may enjoy our otherConversationsposts, including: